Cloud Native Microservices
At Mechanical Rock, we build Cloud Native Solutions, in small teams. We find building using microservice patterns highly effective to simplify our overall approach. Microservices help us to reduce the cognitive load when dealing with complex systems. Furthermore, serverless technologies provide a natural fit for building microservice architectures that are not only decoupled and highly scalable, but also easy to reason about.
Microservices have a long history, with roots in SOA, and distributed computing. Microservices is an emotive subject, with arguments both for and against building microservices from the start.
But how do we characterise a microservice? We do not characterise based on the number of lines of code, but rather on bounded context.
For me, microservices:
- Are event driven
- Are domain oriented
- Decentralise data management
Event Driven
Serverless computing is event driven at it's core. Whether invoking functions, consuming services or building integrations.
Events comprise of two core elements:
- Domain event - the important detail of the event and includes important attributes such as timestamp, and eventType. We use the cloud event specification for defining domain events.
- Envelope - wraps the domain event and captures details of the event transport, such as SNS or EventBridge events.
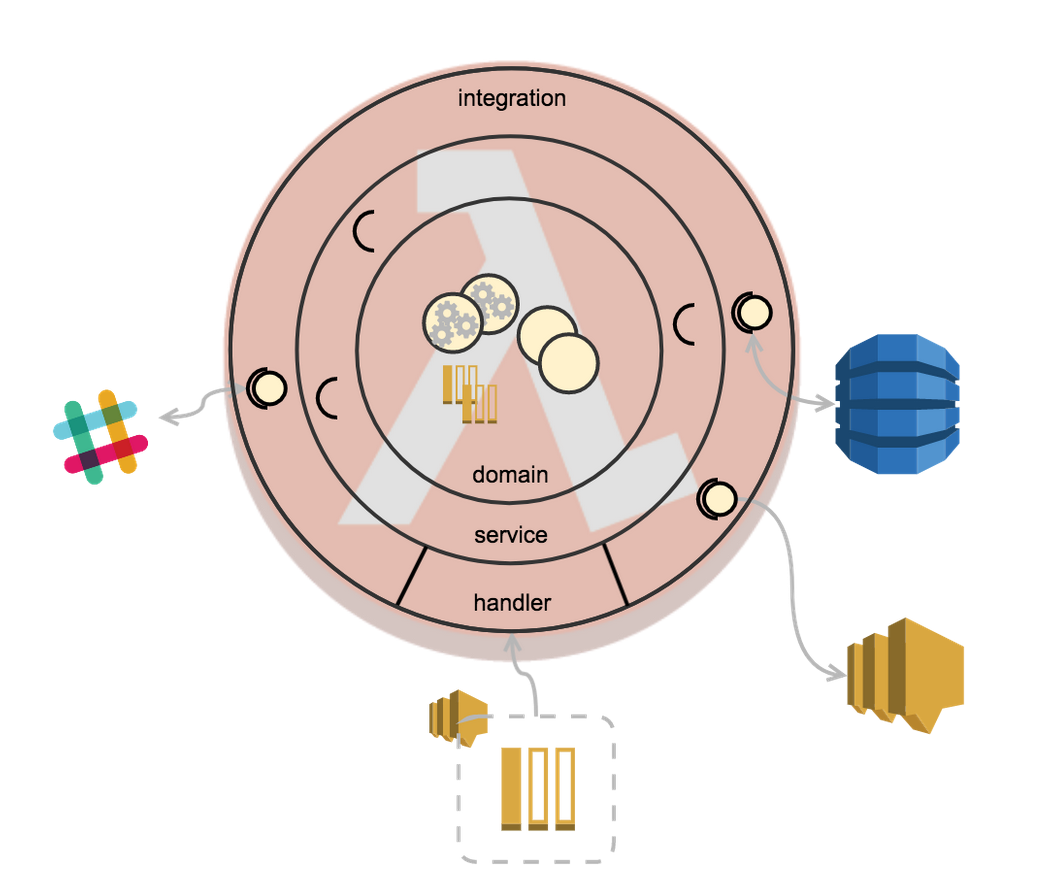
Following clean architecture principles, such as separating envelope unmarshalling from acting on domain events, provides additional flexibility on your deployment architecture. For example, you can use the same domain processing logic to handle synchronous requests sent via API gateway or asynchronously via SNS.
Irrespective of whether you use CQRS, events come in two categories:
- commands
- events
Commands are a request to do something: requestCheckout, updateBalance, createMyWidget. Commands are inherently transient, may be resubmitted multiple times and may/may not result in action being taken.
Events are a notification that something has happened, or a particular state has been achieved: checkoutCompleted, balanceUpdated, MyWidgetCreated. Events occurred at a point in in the past. Depending on how you choose to interpret events, a key part of the semantics, event re-delivery may be possible. For example, accountCreated may be interpreted as "an account has just been created", or "an account was created at a certain point in time". The former has implications on event re-delivery, whereas the latter is immutable and less affected by the temporal difference between when the actual creation occurred and when the event was generated.
Events force you to think about distributed computing - and what the business process should be in the event of failure: "what should happen if payment processing fails?". This is inherent complexity in all systems, but provides a clear boundary around the domain when building anti-fragile systems.
The event schema, is the point of coupling:
- The event schema is 'owned' by the producer.
- Consumers and producers have weak operational coupling: both can be deployed independently, if the event schema is maintained.
- Consumers have strong semantic coupling to the events schema they consume, rather than producers themselves.
- Consumers/producers have weak development coupling: the implementation of either can change independently so long as the schema semantics is maintained.
The rivers-rapids pattern enables service integration and avoids issues of service discovery. The hub/spoke model uses a single, highly available, event bus such as SNS.
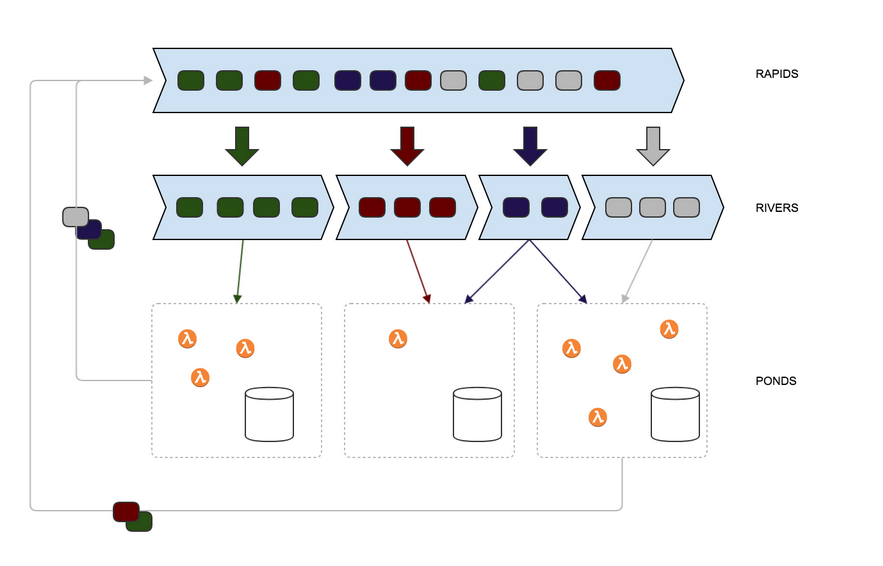
Domain Oriented
Event driven systems complement, and necessitate, domain driven design. The focus on domain events identify natural service boundaries and decouple producers and consumers. As a result, a microservice often comprises of a collection of highly cohesive, tightly coupled functions. Using event boundaries, we are able to disregard the inherent complexity in the production of events the service consumes.
The generation of a CreateManagedAccount contains a large amount of complexity, orchestrating the creation of a new AWS account. If you want to deploy a Config Rule, as part of your cloud governance strategy, to all new accounts you can ignore all that incidental complexity and simply respond to the event.
Using a serverless mindset, we can choose to offload any and all complexity in order to focus on the business domain.
Decentralised data management
Cloud Native development offers a variety of options when it comes to data storage. From general purpose object storage to specialised databases. A microservice architecture enables you to choose the most appropriate storage solution for the use case.
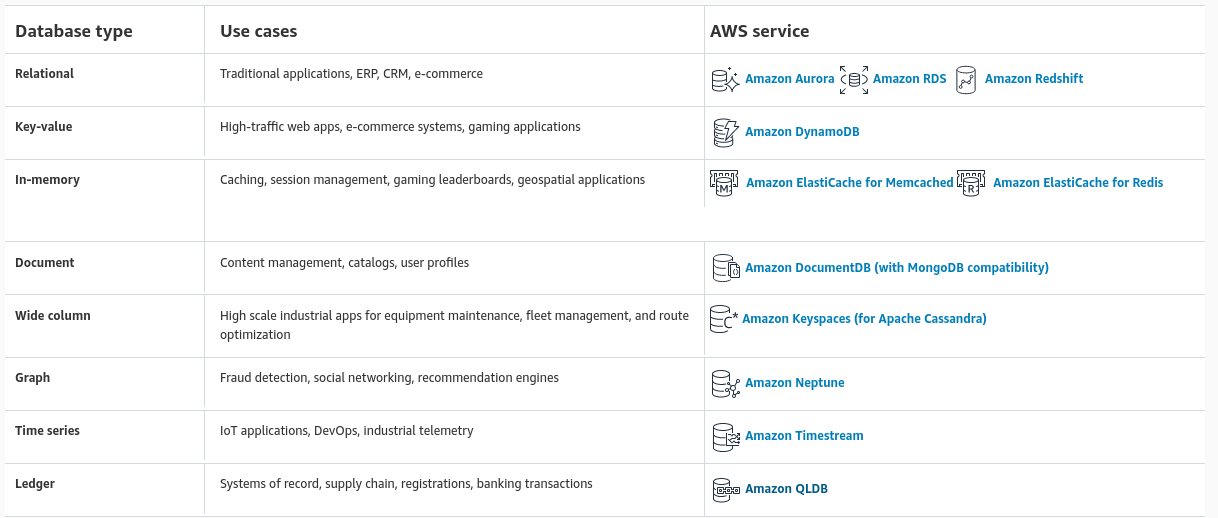
An important characteristic of microservices is decentralised data management. The alternative, a single data store, results in higher incidental, operational and data coupling which are all undesirable. Coupling at the data layer results in a distributed monolith, since any modifications to the data structure have a rippling effect to all the services that depend upon it.
In order to maintain consistency we differentiate between transactional stores and read models. Transactional stores represent a source of truth, where data was produces. Read models, in contrast, consume data from a transactional store to produce a suitable representation for consumers.
A single microservice may reference both transactional and read model data. Transactional data directly correlates to the domain events produced by a service, whereas a read model relates to events consumed by the service.
In event sourced systems, the event log is the transactional store and all other state form read models that can be re-built from the event store. When integrating systems, a read model is used to reference external data, usually for performance reasons, when direct system-to-system API access is undesirable.
By maintaining a clear separation between transactional and read-model data, it enables flexibility whilst minimising the risks associated with data duplication. A read model can always be re-built from a transactional store which improves operational flexibility: rather than perform complex database migration operations, an alternative is to re-hydrate a new instance from the transactional store.
Conclusion
The costs of microservice development are far outweighed by the benefits in a cloud native landscape. By focussing on domain-oriented events we can achieve cloud scale purely focussed on the business rules. By carefully considering events, message redelivery and immutability many of the issues regarding distributed computing can be mitigated easily. Event driven systems are naturally eventually consistent and the shift in focus becomes an asset.
Lets get started on your next Cloud Native solution!