Technical Debt: The First 50 years
Technical debt is a term used by engineers to describe the general friction they encounter in working with software. It stands as a signpost for all the bad design decisions or compromises that have been made in order to accomplish what they need to achieve. Technical Debt itself can't be measured but most engineers will agree that it has an impact on the ability to both deliver and operate software; the four-key metrics presented in the DORA report can act as a suitable alternative. It is easier to argue for investment in specific areas if they can be shown to have an impact on a measure that the business understands to be linked to performance and therefore the profitability of the business.
Technical debt isn't always a bad thing. It makes perfect sense for a company to accrue technical debt at a faster rate if it is done in service of a specific goal e.g. reaching profitability faster, or to lower time-to-market. Issues arise when these goals are not well defined because they allow for technical debt to grow without a clear understanding as to when it becomes appropriate to pay it off. This will eventually have an impact on software delivery performance, and the business is then at risk of a competitor out-performing them. Clear communication, alignment on strategy, trust, and integrity between engineering and business functions is therefore critical to managing technical debt effectively.
From a practical standpoint, technical debt is fundamentally about coupling. Coupling prevents production of value from occurring indepedently, instead requiring careful coordination between producers. This coupling can occur at multiple areas in the software development process. It can manifest as a team being dependent on another team to perform some task before they perform their own task. It could involve needing to significantly modify a service before they can introduce a new feature. Reducing coupling increases production of business value, as it removes bottlenecks from the system. Whilst not reducing technical debt this does reduce the impact. There are multiple ways software development organisations can rearrange themselves and their code in order to reduce coupling and contain the effects of technical debt. Software teams need to realise that all code is a liability that accrues interest and comes with an opportunity cost.
Debt . . . . that peculiar nexus where money, narrative or story, and religious belief intersect, often with explosive force. - Margaret Atwood
Technical debt is an infamous subject in software development. The common understanding is that we accrue it by some series of Faustian pacts; short-cuts are taken in order to deliver a feature sooner, with the underlying assumption that additional features will take longer to complete. A development team that continues to accrue technical debt will eventually find time taken to deliver the next feature will begin to approach infinity. In defiance of what is an obvious problem to the average developer, business stakeholders are often loath to address it. Technical debt is unyielding to measure and resistant to containment due to its nature as an abstract concept. If developers wish relief from technical debt, a better way must be found to describe the cost in real terms.
There is a long list of potential consequences for allowing the unrestrained accrual of technical debt. A reduction in the ability to deliver features (usually referred to as 'velocity') is chief among them. Knowing the consequences of even the smallest change to the system becomes difficult, with minor changes providing an opportunity to observe the butterfly effect. The engineer that coined the term technical debt, Ward Cunningham, explains that the core of technical debt is understanding. This lack of understanding prevents engineers from safely modifying a system, and handicaps our ability to prevent outages. When those outages eventually occur (and they will), the knowledge deficit will frustrate any attempts at triage.
I have a theory, which is that we struggle to get the time allocated to pay down technical debt (or improve deploys, etc) because to biz types we basically sound like the underpants gnomes. step 1 ... pay down technical debt. step 2 ... step 3 .. PROFIT - Charity Majors, CTO @ Honeycomb.io
Persuading stakeholders to address technical debt is fraught with difficulty. Requesting to pay down technical debt is akin to asking someone to trade something they confidently reason has some value, for a loose promise that if and when they ask for something else later, it may be easier to deliver. It is little wonder that most technical debt doomsaying fails to convince anyone, notably in the low-trust terrain that forms the modern enterprise. The benefits of paying down technical debt are often presented in a nebulous way, which is in contrast to the concrete nature of getting a feature out to market sooner. Technical debt may be a murky concept, but that does not mean that the benefits of paying it down are. If we want technical debt to be taken in earnest, we need to get better at gauging the effects and presenting a case for removal that has discernible benefit.
If I owe you a pound, I have a problem; but if I owe you a million, the problem is yours. - John Maynard Keynes
Debt, The First 5000 Years (Graebar, G. 2011) presents some interesting ideas around debt that are applicable to technical debt. The primary thesis of the book is that economies did not spring from barter systems as is commonly thought; economies instead start with a system of promises and IOU's which are later formalised through currency. At the core of this is trust; currency is only effective among a society so long as everyone can agree on its worth. A corollary to this is that barter systems do exist but they commonly occur between parties that do not trust each other. This is suspiciously close to how technical debt is often handled at most companies: two warring factions, engineering and management, bargaining over how much time can be allocated between feature development and refactoring. It therefore stands to reason that there are two ways to improve the situation; 1) increase the level of trust between the two groups, and, 2) find a way to quantify technical debt. Ideally we would do this with dollar figures but this has evaded far greater minds for the better part of the last half-century, so we are unlikely to solve this problem here. Instead we will nominate suitable proxy measurements that are serviceable in its absence, and some ways in which we might restrain the effects of technical debt.

The Tech Debt Quadrant via Martin Fowler
It may be impossible to measure the intangible technical debt, but this property does not always extend to its effects. We can find another measurement (or more) that can act as a suitable proxy. This is not dissimilar to maintenance practices in heavy industry. You can never know for certain when a piece of equipment is going to fail, but you can measure how well maintenance crews are adhering to a planned maintenance schedule. In most cases this is a reasonable indication of equipment health (Weber, A. 2005). What measures could we identify that could act as reasonable proxies for the amount of technical debt across one or more software systems?
If we are to find a substitute measure for technical debt we first need to figure out what attributes it would have. For a measure to be beneficial it must be difficult to exploit for individual gain at the expense of the business. Any metrics we choose should have as few side effects as possible. Ideally such such a metric should have a positive correlation with software best practices. Reducing technical debt via some proxy (whatever form that takes) is not practical if it conflicts with good hygiene (e.g. writing tests).
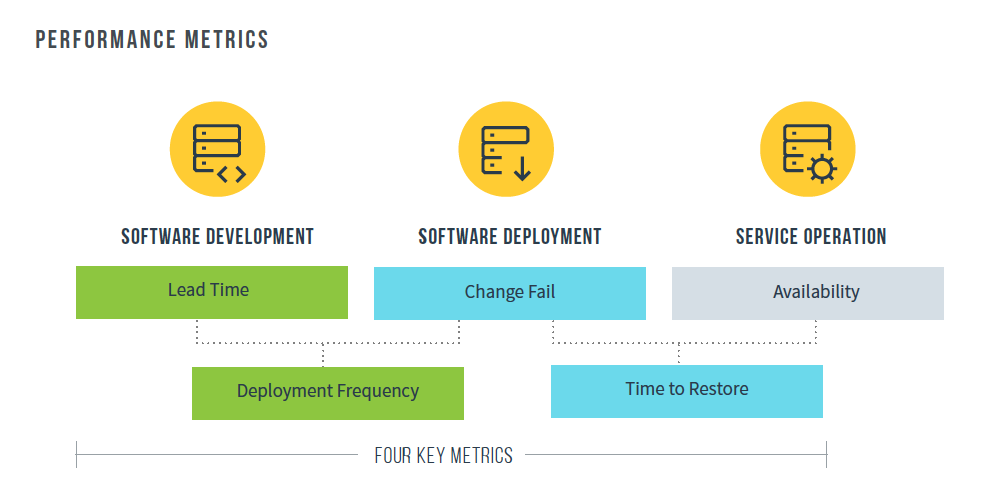
I believe a suitable proxy for technical debt can be found in existing literature on software delivery. The State of DevOps Report (Forsgren, N. et al. 2018) produced by DevOps Research and Assessment (hereby referred to as "the DORA Report") is compiled annually and details the habits of high performing software teams. It is one of the most rigorous studies on software development, produced from surveying and observing hundreds of teams across the world. If we are to come upon a satisfactory measure of technical debt, it would likely be in the DORA report. The report distinguishes two key measures of software delivery performance; throughput and stability. Throughput is measured via deployment frequency and lead time for changes. Stability is measured via time to restore a service and the change failure rate. I believe that change lead time and time to restore service are useful signals of the level of technical debt a project has accrued. Both of these marry well with the effects of technical debt discussed earlier which included decreased velocity and increasingly risky changes.
Code bases that indiscriminately accrue technical debt will find that additional changes will become larger. This is due to the additional refactoring that is needed to accommodate additional features. Larger changes cause two things to happen. An increase in larger changes results in fewer smaller changes, meaning the overall number of changes that are flowing to production decreases e.g. deployment frequency diminishes. Secondly, as we increase the average size of a change the risk of an unsuccessful change increases, and we could expect this to be reflected in the change failure rate.
Furthermore, the DORA report categorises teams into four groups (Elite, High, Medium & Low) against their performance in the four key metrics. The report additionally states teams categorised as high performers were 40% more likely to have low technical debt, although it isn't explicitly stated as to what constitutes technical debt for the purposes of the report.
If a tree falls in a forest, and nobody is around to hear it, does it make a sound? If a service fails for five minutes at midnight, and nobody was using it, did it really go down?
This poses an interesting question; if software requires no additional features, and is never in need of repair, is it free of technical debt? Imagine two bodies of work. One has the former traits, along with the reputation for having been terrible to work with by the authors. The other is a more mediocre example of software development, currently in active development and incurring under 5 hours of downtime per year. Which system has more technical debt? If I hold to my previous definition, I would say the first system has less technical debt. But I guarantee that many would argue in favour of the second. The lack of development on the first system may be due to developers avoiding making changes to it. This would seem to imply the technical debt of a system is a measure of potential which is only zero when the next change to make is to turn it off.
Knowing when something may be turned off is at the core of the problem of technical debt. The first pillar of the AWS Well-Architected Framework (Carlson B. et al. 2018) is entitled "Operational Excellence", and stresses the importance of understanding the priorities and goals of a system. This is an absolutely critical function to knowing whether a system is worth maintaining, and unfortunately many enterprises have a poor understanding of this. Don't believe it? This can be exposed with one simple question; What are the set of circumstances that would need to occur to lead you to decide to turn this system off? An ideal answer would start by explaining the core business problem that the system solves, the value it creates, and how it fits within the wider ecosystem of development at the company. A brilliant answer would provide evidence that such a conversation occurred during the conception, but I have yet to find a group of engineers that were planning for death before birth. It would also be easy to understand how discussing the deprecation of not-yet-developed software might be considered political suicide given the significant expense that would be incurred to write it. Which - once again - exposes the presence of a trust deficit between engineering and business.
Furthermore, this brings to mind how we would utilise these metrics in a system that will continue to be used in the foreseeable future but isn't undergoing rapid change and remains stable.
- Lead Time For Changes would trend towards zero; no changes means no lead time.
- Change Failure Rate would trend towards zero; no changes mean that no changes can fail.
- Deployment Frequency would trend towards zero; no changes (often) mean no deployments.
- Time to Restore Service; assuming the system is indeed stable (humor this), this would also trend to zero as the system would never exercise the need to be restored.
A perfect system would therefore trend to zero on all measures but we know such a system does not exist; all systems fail at some point, resulting in a need to restore a service. Services in cloud-native architectures tend to function as distributed systems and this may lead to emergent behaviour. Our services will likely learn to fail in ways we could have never predicted once we step away from them, and this increases the chances of an unpleasant house-call from the technical debt-collector. For this reason, introducing some level of instability in order to find opportunities to increase resilience is a critical activity for maturing systems; an activity commonly referred to as 'chaos engineering'. This is generally less important to perform for actively developed systems - deployment of changes often involves code modification, traffic-shifting and DNS propagation - all of which is inherently chaotic to begin with. Teams with maturing systems may find that their best introduction to chaos engineering is to schedule regular deployments without any changes in underlying source code. At the very least, it will ensure that the development team does not wait six months to find out the deployment pipeline has stopped working.
This addresses part of the technical debt problem for existing systems but does not give any insight into solutions for systems in active development. Google and AWS are interesting to examine because they have taken contrasting methods to team organisation in order to manage technical debt. I refer to "Site Reliability Engineering" and the "Two Pizza Team" respectively.
The Google Site Reliability Engineering model is one means to place bounds on technical debt. A development team should be able to reach a consensus as to what are acceptable limits to change-lead-time and MTTR. If these limits are exceeded, it should be acceptable for the development team to focus on reducing them until they are within a tolerable range. Beyer, B. et al. (2016) offer a similar concept called "Error budgets". Specialist engineers are deployed to increase the reliability of critical services that have often been developed by other business units. These engineers assume on-call duties for the service provided that the service meets a minimum standard of stability. If this minimum standard is breached the engineers are within their rights to refuse support until the system can meet it. A development team could enter into a similar contract to relieve technical debt.
Specialisation is another method to restrain technical debt from affecting development velocity, and nowhere is this strategy more obvious than in the AWS 'two pizza team'. For a team of twenty engineers, sharing responsibility across twenty systems may feel like working on a crowded train. Drawing boundaries within the system and assigning responsibility for a particular subset of the group is how we commonly manage this. This works well provided that each smaller team still remains large enough to manage the burden of the subsystem. All we have done is distribute our engineers efficiently and ensure they are capable of delivering independently. Managing your domain boundaries in this way can be effective in reducing mean-time-to-repair and change-lead-time. This may not remove technical debt, but managing it becomes easier.
Blessed are the young, for they shall inherit the national debt. - Herbet Hoover
The value of code comes from the problem it solves and the business value it generates, but code itself is ultimately a liability. Maintaining a body of software becomes increasingly difficult as it ages and becomes larger in size. This is further aggravated by the reality that software engineers are not tethered to their creations. They leave and new engineers take their place. New engineers need to understand the legacy left by the predecessors sans the education of having built the system in the first place. It is unreasonable to expect that a new engineer is going to be as effective as the seasoned veteran. We recognise nobody joins a new company with knowledge of its internal processes, politics and three-letter-acronyms, and so we should expect the same of its software systems. Reducing the amount of learning required to be effective is a suitable means to ensure that turnover does not affect the mean-time-to-repair and change-lead-time. Both the AWS and Google approaches address this; two-pizza-teams place bounds around the amount of service-related knowledge any team member would be required to know, and SRE practices ensure teams do not become encumbered by poorly operated services. Another way this is addressed is by using popular open-source frameworks; it is cheaper to recruit a competent react.js developer than it is to train someone on a custom in-house framework. The logical conclusion to draw here is that in ideal circumstances the minimum amount of code should be written to derive value, which would be unique to the particular business problem. To write more beyond that would be taking on an additional liability for no improvement in outcome.
https://vincentdnl.com/ Technical Debt by Vincent Déniel
Relying on cloud vendors for specific managed services could be considered a close relative to dampening the effects of technical debt through smaller teams and specialisation. The architectures that were once the territory of companies with a cast of thousands are now within the reach of a trio of computer science dropouts. Technical debt is still amassed when relying on services from a cloud provider. There is always the risk a service will be deprecated, or that it will be modified, or that it will no longer be suitable for our needs, but this is often insignificant compared the expense accrued when hosting the service ourselves. We would become responsible for the implementation, for maintenance, for the politics of prioritising new features among various internal stakeholders, and be held accountable for when the service inevitably fails. This a colossal amount of nonsense to suffer for a service that does not grant competitive advantage. If technical debt is inevitable (and I believe it is), I would rather acquire it in service of providing functions that are critical to business goals.
Debt certainly isn't always a bad thing. A mortgage can help you afford a home. Student loans can be a necessity in getting a good job. Both are investments worth making, and both come with fairly low interest rates. - Jean Chatzky
Not all debt in life is necessarily bad and the same can be said of technical debt. Debt in service of an education has historically proven to be a sensible decision, as it opens up opportunities for returns that would not have been possible without it. A company that has never been profitable is probably better off concentrating on becoming profitable then obsessing over their software architecture. Taking upon some debt in service of this goal is worthwhile. The caveat is this must be a conscious decision. It is unwise to take out a loan out if you will be unable to get a return-on-investment. Yes, there is always some level of uncertainty in a new venture and value is often found in the unknown, but taking no steps towards due-diligence is waving the white flag to negligence.
This brings us around to a recurring theme in the subject of debt: trust. Technical debt is accrued via a lack of trust between engineering and other parts of the business caused by communication dysfunctions on each side. The business fails to clearly articulate strategy and goals, and in turn engineering departments fail to contain technical debt because they are unable to anticipate the direction of the business. Engineering departments then fail to drive appropriate organisational change because they are unable to articulate the impacts with figures that the business will be able to understand. Engineering may not be able to articulate the cost of this, but the business can certainly understand that its ability to deliver software is tied to its ability to charge for it. Software delivery metrics as proposed by DORA are therefore likely to be as convincing a measure as any other.
Technical debt is a qualitative statement that indicates a mismatch in the expectations between engineering and its place in delivering value to the business. Attempting to minimise technical debt indiscriminately is a useless endeavour because whether a specific debt is helpful or harmful is entirely dependent on context, and neither engineering nor the business are likely to have an adequate understanding of this context if they are not communicating effectively in good faith. Engineering departments should work with the business to manage it effectively and ensure that the amount of value provided to its customers is maximised.
References
[1] Graeber, G. (2011) Debt, The First 5000 Years. Melville House Publishing
[2] Weber, A., Thomas, R. (2005) Key Performance Indicators: Measuring and Managing the Maintenance Function. Ivara Corporation.
[3] Forsgren, N., Humble, J. and Kim G. (2018) Accelerate: State of DevOps: Strategies for a New Economy. DevOps Research & Assessment.
[4] Carlson B., Fitzsimons P., King R., and Steele J. (2018) Well-Architect Framework: Operational Excellence. Amazon Web Services.
[5] Beyer, B., Jones, C., Petoff, J. and Murphy, N. (2016) Site Reliability Engineering. O'Reilly Media.