Solving Global Latency With PostgreSQL Logical Replication
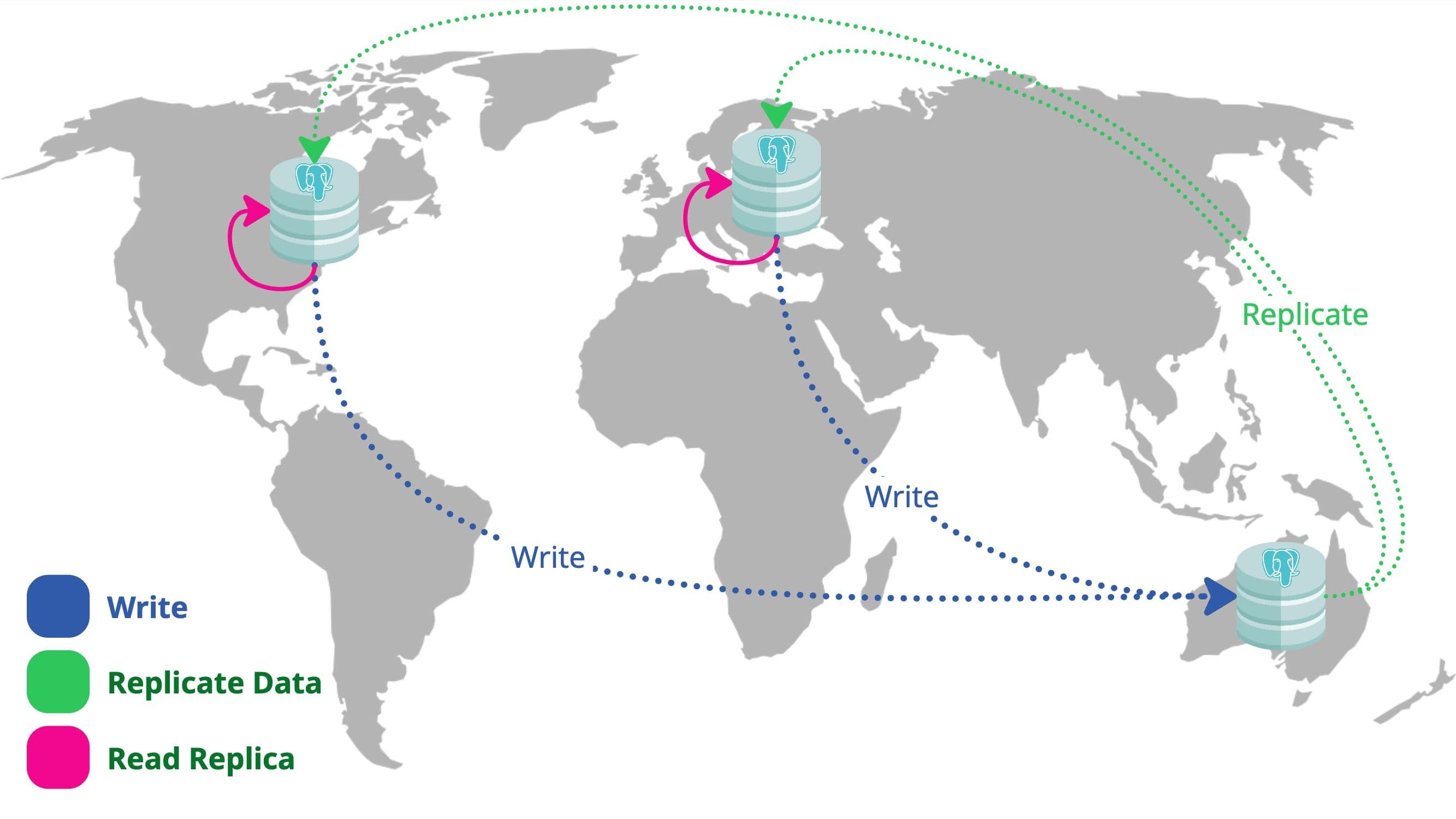
Table of contents
- A Regional Architecture Clash
- Getting Hands-On with PostgreSQL Logical Replication
- The Result
- References & Further Reading
A few months ago, we released an application that started gaining some great traction. Initially, our user base was mostly in Australia where our engineering team is based so it made sense to architect our core infrastructure within the AU region. At launch, everything was humming along nicely.
Then things started to change.
Adoption picked up overseas. Customers from the US and EU began trickling in, and shortly after, performance metrics for international users started looking grim. Particularly around first load times and anything touching the database. We invested a lot in frontend performance, global CDN distribution, and network peering, but there's only so much you can do when the database is locked to a single region 14,000 km away from half your audience.
That's when we knew we had a problem to solve at the data layer.
Keep reading to see how we made a 2,900% improvement in speed for US and EU users.
A Regional Architecture Clash
Our stack was already containerised and designed for horizontal scalability, so spinning up app instances in new regions wasn't a huge problem. But the database... that's where things got tricky. Our PostgreSQL cluster was region-bound, tightly coupled to AU. We weren't using any form of cross-region replication. Write latency for overseas users was brutal. Even worse, reads weren't much better because we didn't have any local read replicas.
We sat down as a team and threw around a few possible architectures:
Option 1: Fully independent vertical stacks (one per region)
Each region gets its own stack, its own database. Data is siloed. Some form of eventual sync (maybe via APIs or messaging) could be used for consistency.
- Pros: Low latency, total regional autonomy.
- Cons: Complex data sync, fragmented source of truth, hard to reason about global state. More operational cost, developers have to be mindful of seperate stacks.
Option 2: Single write master in AU, read replicas (logical) in US/EU
Keep a single source of truth but allow regional reads via logical replication.
- Pros: Centralised writes, global reads, consistent source of truth.
- Cons: Slightly stale data in replicas, potential failover complexity. 3x DB storage (be mindful of this and calculate exponential growth in your scale to accept the cost of storage).
Option 3: Comprehensive caching layer
Introduce a strong regional caching layer using something like Redis or a distributed in-memory cache.
- Pros: Quick wins, great for high-volume read patterns.
- Cons: Doesn’t solve all cases, still bottlenecked on writes and cache misses.
After hashing it out, we landed on Option 2. Logical replication gave us a way to reduce read latency without sacrificing a centralised, consistent write model. It was the best mix of performance, simplicity, and operational safety for our use case. We were satisfied with potential scale costs by storing 3x the data at different DBs.
Getting Hands-On with PostgreSQL Logical Replication
Why Logical over Physical?
| Feature | Logical Replication | Physical Replication |
|---|---|---|
| Granular control | ✅ Table-level | ❌ Full cluster only |
| Version compatibility | ✅ (some leeway) | ❌ Must match exactly |
| Performance overhead | ❌ WAL decoding cost | ✅ More efficient |
| Supports multi-primary | ✅ (with effort) | ❌ One primary only |
We were already running PostgreSQL 16, which includes mature support for logical replication. Logical replication works at the level of individual tables, streaming data changes from a source (publisher) to one or more subscribers. Unlike physical replication, it allows for selective replication and more flexibility which is what we needed.
Here's how we made it work:
1. Enable Logical Replication on the Publisher (AU Region)
First, we checked that our PostgreSQL instance was configured for logical replication.
SHOW wal_level;This needs to be set to logical. If it's not:
wal_level = logical
max_replication_slots = 10
max_wal_senders = 10Then restart PostgreSQL. On managed services like RDS or Cloud SQL, you can configure this via parameter groups.
2. Create a Replication Role
CREATE ROLE replicator WITH REPLICATION PASSWORD "strongpassword" LOGIN;Grant access to the tables you want to replicate.
3. Create a Publication on the Publisher
CREATE PUBLICATION global_pub FOR TABLE customers, orders, products;You can also use FOR ALL TABLES if you want broad replication.
4. Set Up the Subscriber (e.g. US or EU Region)
On the regional replica instance:
CREATE SUBSCRIPTION global_sub
CONNECTION "host=your-au-db-host user=replicator password=strongpassword dbname=yourdb";
PUBLICATION global_pub;This begins replication immediately. PostgreSQL handles initial table sync automatically unless you disable it with copy_data = false.
🔥 Pro tip If you create a new table, alter table, drop a table... Run
ALTER SUBSCRIPTION subscription_name REFRESH PUBLICATIONon your subscriber databases to sync changes.
The Result
After deploying logical replication to our US and EU application stacks, we saw a noticeable improvement in read performance for those regions. Initial page loads dropped from ~6.2 seconds to ~200ms for authenticated users. The database was no longer a global choke point.
⚡ 30x latency reduction
There's more we could do, like bi-directional replication or smarter caching strategies, but this step alone made a huge difference and unblocked our global expansion plans.
Logical replication isn't a silver bullet, but it gave us the tools to scale in a direction that matched our growth and engineering bandwidth. If you're in a similar boat, reach out and we'd be happy to help!
Lessons and Observations
- Initial sync was heavy. Depending on your dataset, the initial data copy can be resource intensive. Plan for it. We scheduled ours during low-traffic windows.
- Schema must match on publisher and subscriber. PostgreSQL logical replication is unforgiving about schema drift.
- Replication lag is minimal for most read-heavy workloads, but be mindful of your use case. If you’re trying to run eventually-consistent workflows or local analytics, it's fine. But for transactional reads, you'll need to build in awareness of staleness.
- Monitoring is critical. Use
pg_stat_replicationandpg_stat_subscriptionto keep an eye on replication lag and errors.
Future Work
- Explore bi-directional replication or solutions like BDR (Bi-Directional Replication) if multi-master writes become necessary.
- Experiment with read/write routing logic to avoid staleness in critical flows.
- Continue to improve observability tooling to capture edge-case replication drift and better alerting.