Serverless Express Without The Express (Or Lambda)

Introduction
It often comes as a surprise to many developers that you don't actually need lambda when building certain kinds of API's with API Gateway. Many simple CRUD applications don't need it at all and can get away with service integrations to DynamoDB. In doing so, you no longer need to pay for the cost of a lambda execution, or incur additional latency from needing to invoke a lambda function. If all your lambda function does it store data in DynamoDB, you probably don't need that lambda function. The serverless express guestbook application that I've been using as an example is a good case study in this. In a previous installment, we implemented X-Ray tracing and noticed that storing and retrieving comments from S3 is quite slow. Let's refactor that to use DynamoDB, and remove the lambda functions in the process!
All code for this tutorial is available here. Aside from the tools required from previous installments (The AWS SAM CLI), it will help to have Postman installed to exercise the API later.
Database Design
Let's begin by designing the DynamoDB table. Theses are the following access patterns I want to cover;
-
I want users to be able to post comments.
This will logically require a field to hold author and message data.
-
I want users to be able to delete their own comments.
This means I will need a way to uniquely identify a particular comment, via an ID field.
-
I want to be able to list comments by user, most recent comments first.
This will require some sort of time field.
-
I want to able to list all comments, most recent comments first.
This adds nothing new field-wise (or does it?), but it may influence our indexing.
I've settled on the following fields/indexes
- pk: This is the partition key - and I will store author data in this.
- sk: This is the sort key - and I will store the comment ID in this field. Together, these two fields uniquely identify every comment in the database, and allow me to CRUD a particular comment
- m: This field will contain the comment message.
- d: This will store the time that a comment was made, in epoch (unix) time
- pk_d: A local secondary index (LSI) that uses 'd' to sort the entries. This allows me to query a users comments in order by the time they were made
- t: A static value that represents the type of entry. This will contain the string 'comment'
- t_d: A global secondary index (GSI) to sort all comments by the date they were made. This is required to be able to query all comments and return them in the order they were made. Table scans do not return items in global order (only by partition order), so we require an additional partition key that all comments can belong to, and an associated sort key.
To create the table in CloudFormation, you can use the following definition.
Database:
Type: AWS::DynamoDB::Table
Properties:
AttributeDefinitions:
- AttributeName: pk
AttributeType: S
- AttributeName: sk
AttributeType: S
- AttributeName: d
AttributeType: N
- AttributeName: t
AttributeType: S
BillingMode: PAY_PER_REQUEST
GlobalSecondaryIndexes:
- IndexName: t-dt
KeySchema:
- AttributeName: t
KeyType: HASH
- AttributeName: d
KeyType: RANGE
Projection:
ProjectionType: ALL
KeySchema:
- AttributeName: pk
KeyType: HASH
- AttributeName: sk
KeyType: RANGE
LocalSecondaryIndexes:
- IndexName: pk-d
KeySchema:
- AttributeName: pk
KeyType: HASH
- AttributeName: d
KeyType: RANGE
Projection:
ProjectionType: ALLThe Rest of the Template
Previously we used a lambda function and an HTTP API - we remove both of these and replace it with the following REST API.
GuestBookApi:
Type: AWS::Serverless::Api
Properties:
DefinitionBody:
'Fn::Transform':
Name: AWS::Include
Parameters:
Location: api.yaml
StageName: prod
TracingEnabled: true
OpenApiVersion: '3.0.0'
Cors:
AllowOrigin: "'*'"
AllowHeaders: "'authorization, content-type'"
MethodSettings:
- ResourcePath: '/*'
HttpMethod: '*'
DataTraceEnabled: true
LoggingLevel: INFO
MetricsEnabled: true
ThrottlingRateLimit: 5
ThrottlingBurstLimit: 10This is pretty similar to the HTTP API definition from before but adds a couple of things:
- An explicit stage name of 'prod'
- Enables X-Ray Tracing (not supported yet in HTTP API - but it is on the roadmap)
- Adds some settings around logging and throttling that are not supported in HTTP API (but once again, are on the roadmap)
Finally, we will need two roles to manage read and writing to the database. These will be referenced in our OpenAPI definition, and will be used by our API Gateway service integrations to perform actions against our DynamoDB table. As we are splitting up our methods and endpoints, we can narrow permissions needed by a specific resource/method to a specific set. This ensures each action has the minimum permissions needed to perform the job. This is a massive advantage over using a monolithic lambda function that controls routing - as paths do not have access to more permissions than they require to perform their intended function.
PostCommentsRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Statement:
- Effect: Allow
Principal:
Service: apigateway.amazonaws.com
Action: sts:AssumeRole
Policies:
- PolicyName: root
PolicyDocument:
Statement:
- Effect: Allow
Action: dynamodb:PutItem
Resource: !Sub "${Database.Arn}"
ReadCommentsRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Statement:
- Effect: Allow
Principal:
Service: apigateway.amazonaws.com
Action: sts:AssumeRole
Policies:
- PolicyName: root
PolicyDocument:
Statement:
- Effect: Allow
Action:
- dynamodb:GetItem
- dynamodb:Query
Resource:
- !Sub "${Database.Arn}"
- !Sub "${Database.Arn}/index/*"The OpenAPI Definition
Our OpenAPI template requires several adjustments. Most of these I based off of the (Real World Serverless)[https://github.com/awslabs/realworld-serverless-application] application. At the time this was the only public example I could find of an application that used the OpenAPI version 3 template format successfully.
We start with the following definitions to enable request validation and define CORS headers for error responses. This is a bit more difficult to configure correctly in an API Gateway REST API than is in HTTP APIs; so if you hate CORS, you'll probably love HTTP APIs.
openapi: 3.0.1
info:
title: simple-node-api
description: A simple API for a guestbook application
version: 2019-10-13
x-amazon-apigateway-request-validators:
all:
validateRequestBody: true
validateRequestParameters: true
x-amazon-apigateway-request-validator: all
x-amazon-apigateway-gateway-responses:
# Provide more detailed error message for bad request body errors. See doc: https://docs.aws.amazon.com/apigateway/latest/developerguide/api-gateway-swagger-extensions-gateway-responses.html
BAD_REQUEST_BODY:
responseTemplates:
application/json: '{"errorCode": "BadRequestBody", "message": "$context.error.validationErrorString"}'
responseParameters:
gatewayresponse.header.Access-Control-Allow-Origin: "'*'"
DEFAULT_4XX:
responseParameters:
gatewayresponse.header.Access-Control-Allow-Origin: "'*'"
DEFAULT_5XX:
responseParameters:
gatewayresponse.header.Access-Control-Allow-Origin: "'*'"Then we need to add some definitions to our 'Create Message' endpoint. In it's entirety, it looks like this.
/:
post:
operationId: CreateMessage
requestBody:
content:
text/plain:
schema:
type: string
required: true
responses:
"201":
description: "Successfully created a message."
content:
application/json:
schema:
$ref: "#/components/schemas/Message"
"400":
description: "Bad Request Exception"
content:
application/json:
schema:
$ref: "#/components/schemas/BadRequestException"
"500":
description: "Internal Server Error"
content:
application/json:
schema:
$ref: "#/components/schemas/InternalServerErrorException"
x-amazon-apigateway-integration:
type: aws
uri:
Fn::Sub: arn:${AWS::Partition}:apigateway:${AWS::Region}:dynamodb:action/PutItem
httpMethod: POST
credentials:
Fn::Sub: "${PostCommentsRole.Arn}"
requestParameters:
"integration.request.header.X-Amzn-Trace-Id": "context.xrayTraceId"
requestTemplates:
"application/json":
Fn::Sub: |
{
"TableName": "${Database}",
"Item": {
"pk": {
"S": "$context.identity.caller"
},
"sk": {
"S": "$context.requestId"
},
"d": {
"N": "$context.requestTimeEpoch"
},
"m": {
"S": "$input.body"
},
"t": {
"S": "comment"
}
}
}
"text/plain":
Fn::Sub: |
{
"TableName": "${Database}",
"Item": {
"pk": {
"S": "$context.identity.caller"
},
"sk": {
"S": "$context.requestId"
},
"d": {
"N": "$context.requestTimeEpoch"
},
"m": {
"S": "$input.body"
},
"t": {
"S": "comment"
}
}
}
responses:
"2\\d{2}":
statusCode: 201
responseTemplates:
"application/json": |
#set($inputRoot = $input.path('$'))
{
"id": "$context.requestId",
"author": "$context.identity.caller",
}
passthroughBehavior: never
x-amazon-apigateway-auth:
type: AWS_IAM
security:
- sigv4: []The start of the definition should be familiar territory, but it begins to diverge with the 'x-amazon-apigateway-integration' property. This property is an API Gateway extension to the specification that defines the service integration for this endpoint.
x-amazon-apigateway-integration:
uri:
Fn::Sub: arn:${AWS::Partition}:apigateway:${AWS::Region}:dynamodb:action/Query
httpMethod: POST
credentials:
Fn::Sub: "${ReadCommentsRole.Arn}"
type: aws
passthroughBehavior: neverThe start of the definition includes a few things;
-
uri
This defines the service integration we are going to use. We can see from this example, that we have chosen to use a dynamoDB Query action.
-
httpMethod
Regardless of whether we are reading or writing, most service integrations use a 'POST' http method. This refers to invoking the particular service integration action - not the method of the particular endpoint.
-
credential
Here we have subbed in the ARN of the read comments role that we create in the CloudFormation Template.
-
type
This refers to the particular integration type that we are using - a standard 'aws' integration in this example.
-
passthroughBehaviour
This determines whether non-matching content types are passed through to the integration. I usually default this to 'never'. If a request comes through with a non-matching content-type header, API Gateway will auto-respond with 415 Unsupported Media Type.
Lastly, we define the security of the endpoint. This is done via the 'x-amazon-apigateway-auth' property on each method, in conjunction with security schemes within the components defintion.
Now we need to define a request template.
requestParameters:
"integration.request.header.X-Amzn-Trace-Id": "context.xrayTraceId"
requestTemplates:
"application/json":
Fn::Sub: |
#set($token = $input.params("token"))
{
"TableName": "simple-node-api-Database-5IHXRFDA8AAX"
,"IndexName": "t-dt"
,"KeyConditionExpression": "t = :v1"
,"ExpressionAttributeValues": {
":v1": {
"S": "comment"
}
}
,"ScanIndexForward": false
#if($!token != "")
#set($startKeyString = $util.base64Decode($token))
#set($startKey = $startKeyString.replaceAll("\\""", """"))
,"ExclusiveStartKey": $startKey
#end
#if($!{input.params("maxItems")} != "")
,"Limit": $input.params('maxItems')
#else
,"Limit": 10
#end
}Firstly I've ensured that the X-Ray Trace ID header is propagated into the request via the request parameters. This will allow me to see DynamoDB in the request trace. The next step is to define a VTL mapping template. The templates are defined on a per-Content-Type basis. I've decided to only accept 'application/json', so only one template is present.
The template defines the payload that is sent to the DynamoDB query endpoint, which follows the specification detailed here. Several rows start with a '#' symbol - I've used these to inject additional properties where needed. For example, if the 'maxItems' query parameter was specified, I'll include it in the query, otherwise default to the value 10. I additionally check for a base64 encoded token, and inject it as the ExclusiveStartKey if it is present. This allows the user to paginate through the results provided by the endpoint.
Further information is available on special VTL parameters here.
I've also implemented an endpoint to create comments - which is far simpler. Peruse it at your own leisure. I've left additional endpoints as an exercise for the reader.
components:
securitySchemes:
sigv4:
type: apiKey
name: Authorization
in: header
"x-amazon-apigateway-authtype": awsSigv4This defines a security scheme, namely that authorization information will be the header under the Authorization Key, and that will confirm to AWS Signature V4. This is the correct Authorization scheme when using native IAM controls to invoke API Gateway.
Each endpoint will have the following additional property. This enables AWS_IAM authentication on the endpoint and indicates that AWS Signature V4 is in use.
x-amazon-apigateway-auth:
type: AWS_IAM
security:
- sigv4: []Deploy and Exercise the API
Deploying the API, as always, can be done through a simple sam build && sam deploy command initiated at the root of the repository.
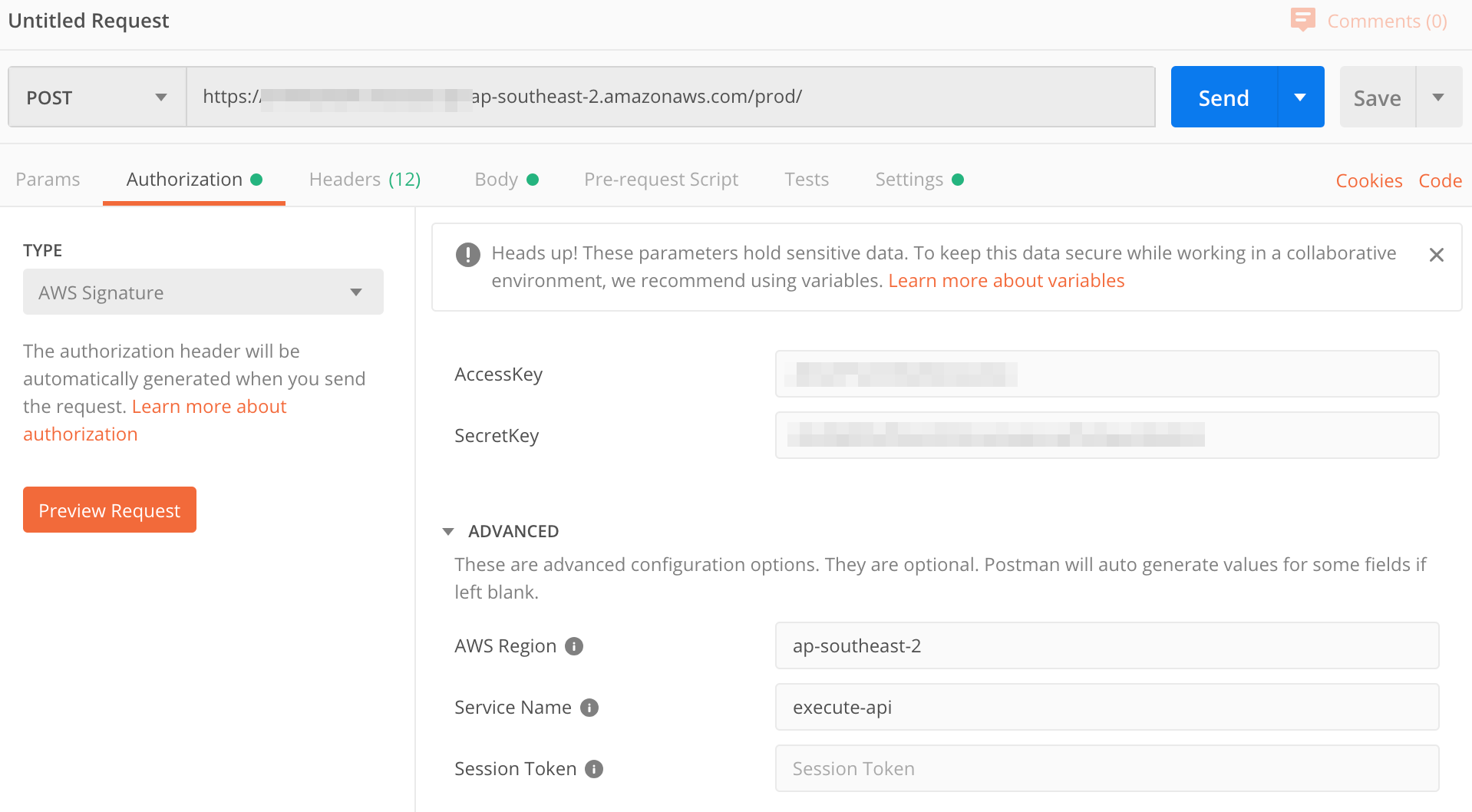
Once the API is deployed, let's use Postman to send some messages. The first thing you'll need to is select 'POST' and then set the neccesary authorization header. To do this, you'll need to select AWS authorization and fill out the appropriate credentials. Assuming that you have been using AWS SAM CLI successfully up till now, you can grab keys from your ~/.aws/config file. This assumes that you have permissions to invoke the API. The auth section should look like the below.
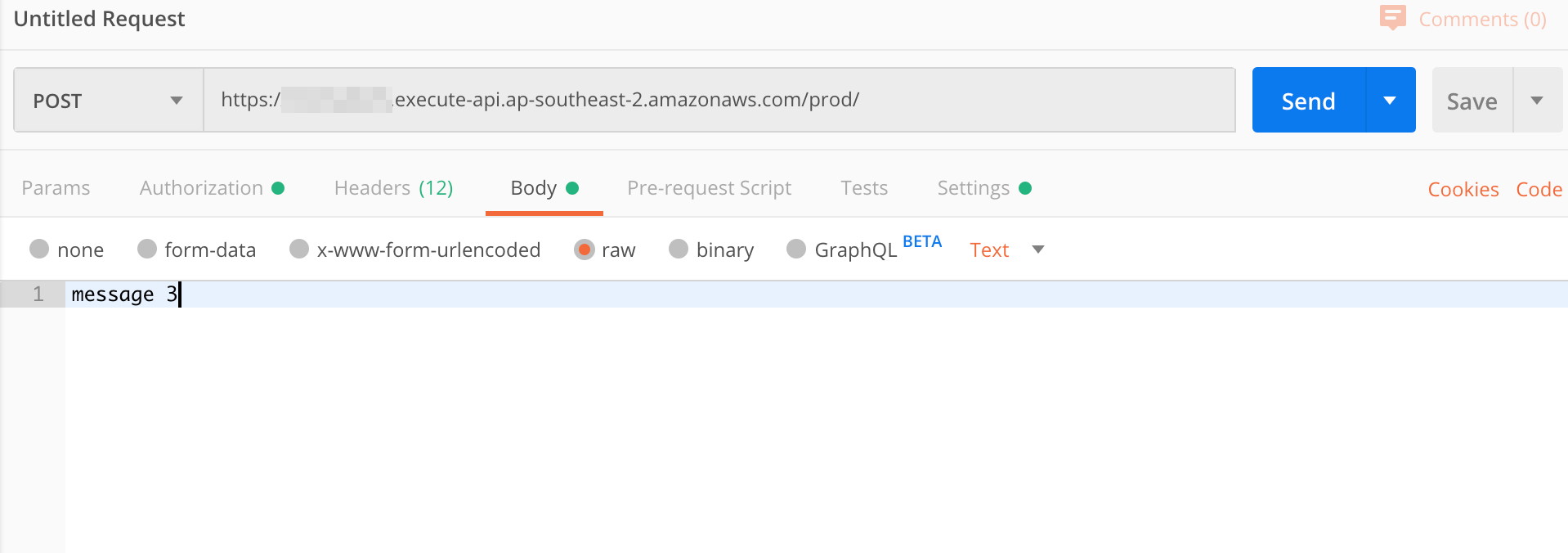
You can post a message by entering some text in the 'body' section. Just make sure you set the content type correctly by setting it to 'raw', and then selecting 'text' from the dropdown menu.
Once sent, you should get a result like the following image.

Performing a GET is similar - you will still need to set the authorization header, but you won't need to enter anything in the body.
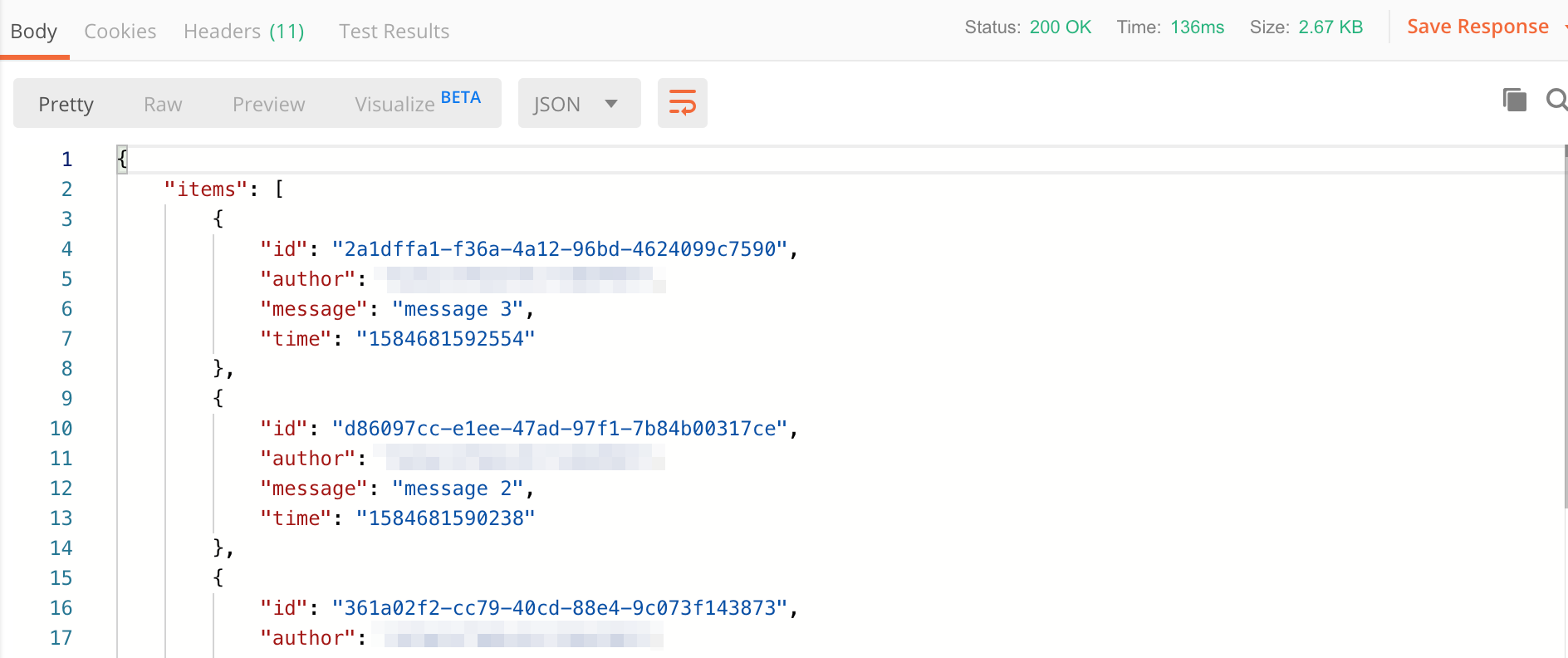
Likewise - you should get a result similar to the following.
We can also check things out in X-Ray. You'll notice the trace-map now looks like the following.
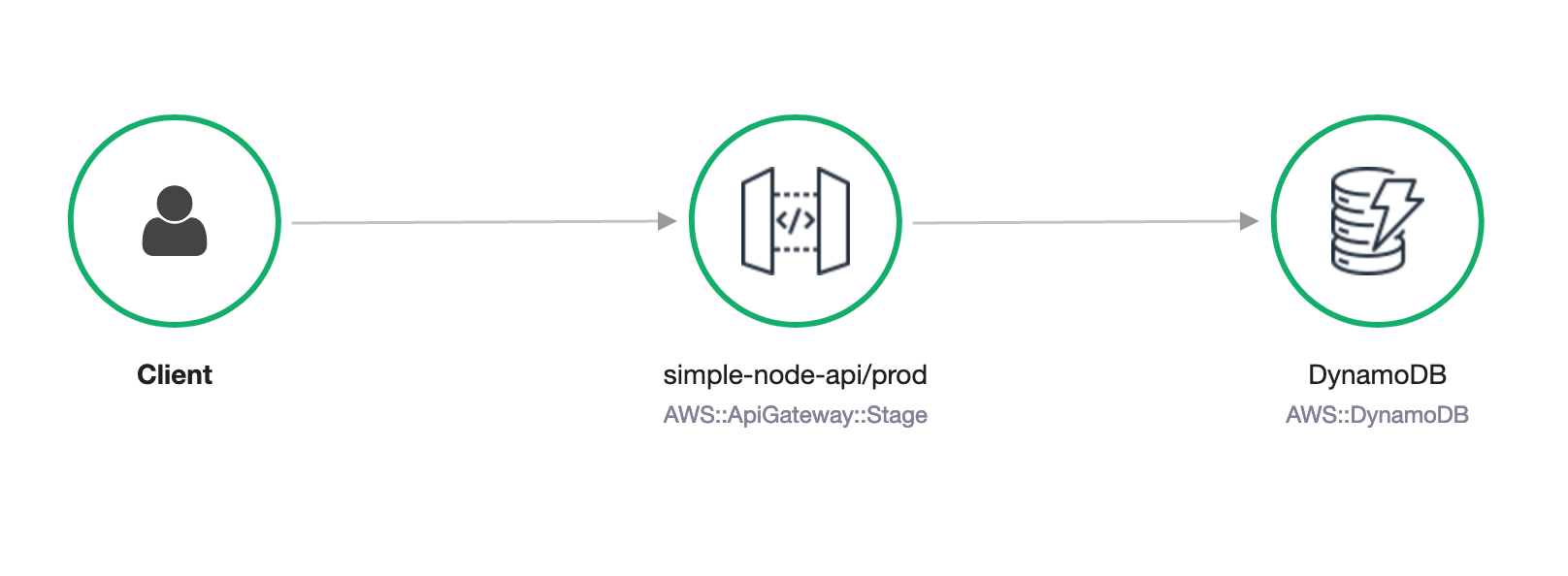
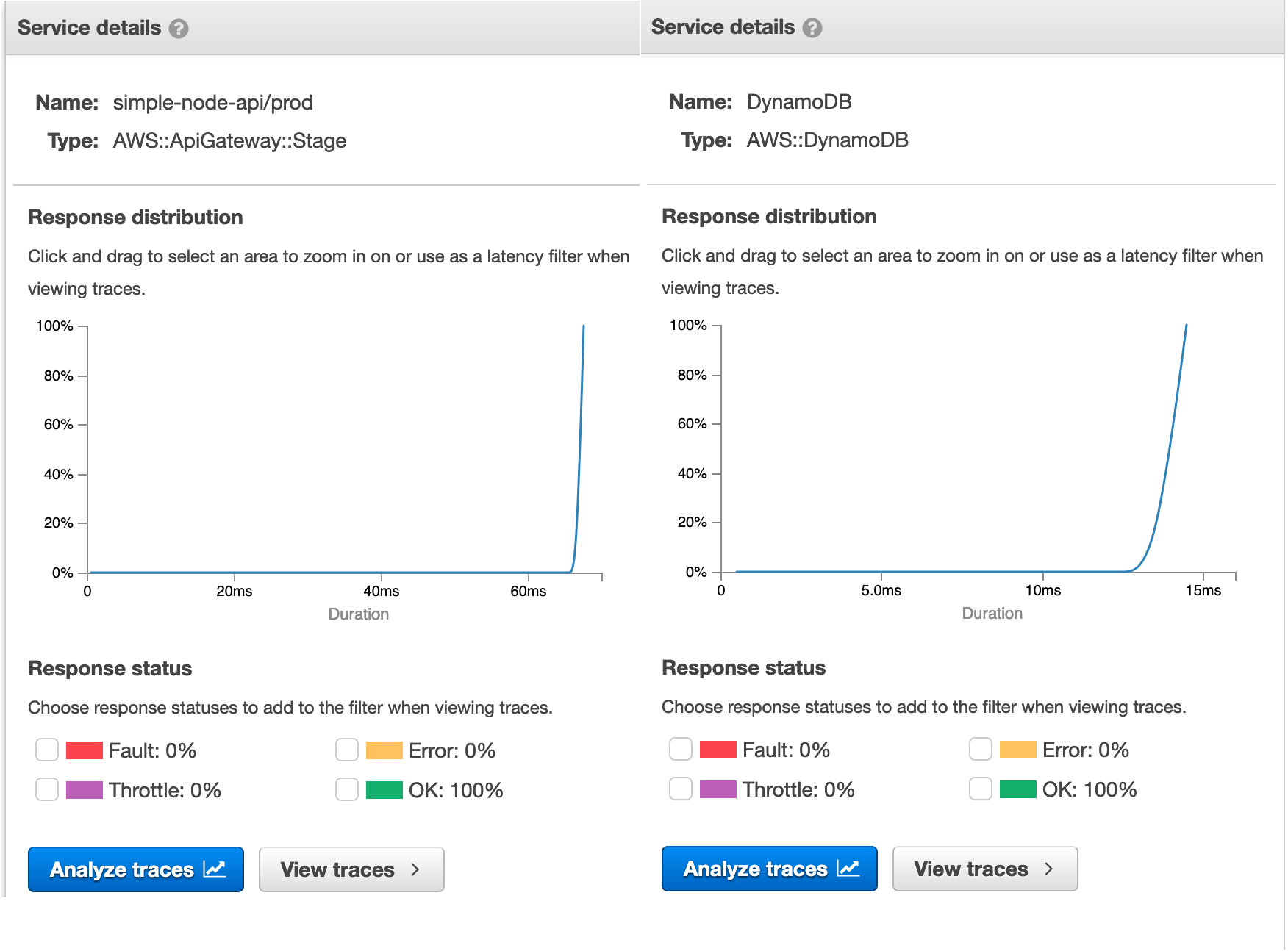
We can review the latency of each request - either the API Gateway as a whole or just the request to DynamoDB.
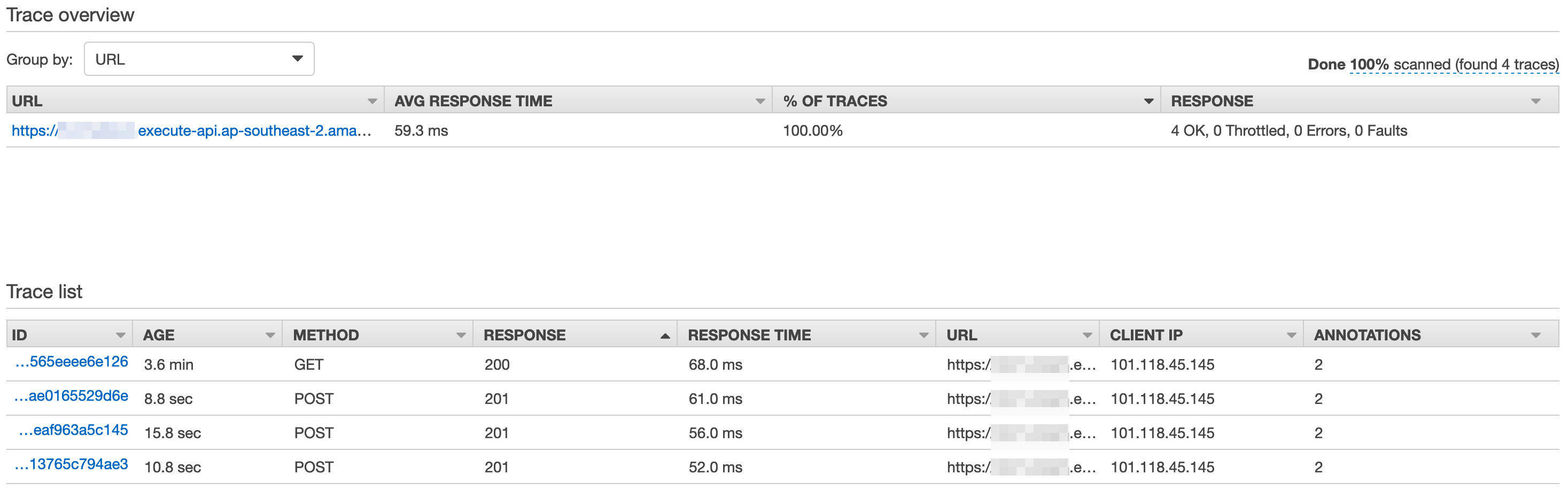
We can list all those traces...
And review a trace for a specific request.
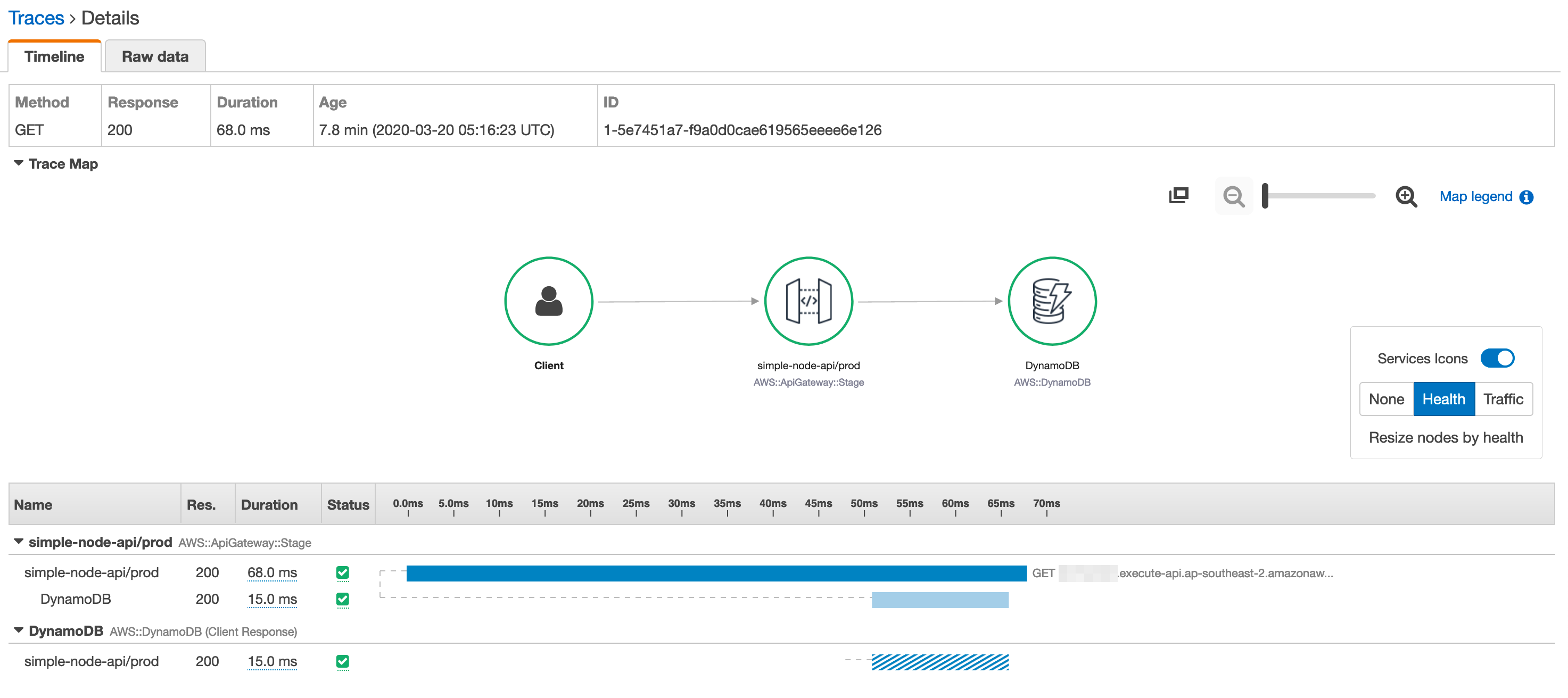
For those who followed our previous installment, you'll remember that to get all of the comments originally took around 1.6 seconds when each comment was stored in S3. This is significantly faster at 60ms per request. That's 26 times faster, which is a pretty big improvement. The moral of the story is to perhaps not use S3 in such a scenario - use DynamoDB.
Other Considerations and Commentary
HTTP API's do not yet have all the features of REST API's. This largely seems to be due to the result of customer feedback; a simple lambda proxy that provides JWT authorization covers a fairly large number of use-cases. Still, it's worth some additional discussion.
HTTP API vs REST API
At the moment HTTP API's do not support direct service integrations but they are probably on the roadmap. AWS has stated that HTTP API's will eventually hit feature parity with REST API's. The performance improvement was derived mainly from switching out S3 for DynamoDB - in a future installment, I will do a more Apples-to-Apples comparision of REST API vs HTTP API. AWS has claimed that HTTP API's are 60% faster than REST APIs, so I expect that HTTP API with Lambda will have comparable performance to REST APIs with Service Integrations - at least for this application anyway.
Authentication - IAM vs JWT
The serverless express applications used JWTs authorization because it is all that HTTP API's support. REST API's have a more robust selection. In this case I chose to use IAM Authorization. I personally prefer native IAM controls, because it lets me piggy-back on to a more robust RBAC mechanism that I do not need to write myself. In practice this can make things complicated, because in practice it can require using cognito identity pools to vend out AWS credentials via a token exchange. As mentioned in prior installments, Casbin (or some other policy engine) can be used if you want to stick to just using JWTs.
OpenAPI Document Pollution
It bothers some developers that they must include AWS extensions in the OpenAPI document. I can understand wanting to keep the document 'pure' from vendor pollution. To do this, it is possible to define the vendor extensions in a separate file, and then merge the two files afterwards as part of your build process. Alternatively, AWS have their own IDL, called Smithy. Smithy can be used to generate an OpenAPI definition file with and without API Gateway extensions. Some users may find this useful if they want to publish their OpenAPI document free from vendor properties that may expose implementation details.
Pagination
There are limited ways to implement pagination when using VTL extensions. In my example, I used base 64 encoding in a vain attempt to hide implementation details, but anyone can simply decode the token. They could then rely on implementation detail that may change in future, which may break their application. The real-world serverless application example instead uses a KMS key to encrypt the pagination data, so that this cannot occur. There is no way to do this in VTL though, so you must use more flexible compute, like lambda, to do so.
Testing
Testing is much harder with VTL - as it requires deploying and exercising the API directly. This is more akin to an End-to-End test, but you may be able to get away with a unit test when using lambda. That said - you should be performing end-to-end testing on your API anyway so I don't normally consider this a deal-breaker, personally.
Instrumentation
A cool side effect of going the VTL path is we didn't really need to write any custom logging or instrumentation code - it's provided entirely out of the box via X-Ray integration, and in-built logging. It's a little more work to do this via lambda functions.
Conclusion
We decided to take a step back and implement our API using REST API. We used service integrations to remove our lambda functions from the equation. We built a CloudFormation template to deploy our API with DynamoDB. We updated our OpenAPI definition with API Gateway extensions, which allowed us to use the DynamoDB service integration. We implemented authorization via native IAM controls. We then sent a few requests off using postman, and review the performance of the application using X-Ray. Finally, we finished with a discussion of the differences between this approach and that of the HTTP API-Lambda method.
Do more with (server)less! Contact Mechanical Rock to Get Started!