How to create a Snowflake DataOps pipeline using AWS

What is DataOps?
DevOps practices have been discovered, utilised and perfected over the past few years to allow speed and agility in software engineering. Despite these advancements in the software engineering discipline, they have not been widely adopted in the data engineering domain. DataOps is a concept that applies DevOps practices to data life cycles to achieve speed and agility whilst delivering trusted and high-quality data. Like DevOps, DataOps minimises manual interventions by codifying data related changes and deployment through automated CI/CD tools. In Snowflake just about everything can be managed via executable SQL statements. This makes schema migration tools like Flyway and Sqitch the perfect devops companion for Snowflake. The schema migration tools are great for creating and managing resources, like grants, databases, snowpipes, stages, tasks, integrations etc. While it is possible to also manage data transformations using flyway (e.g. via tasks), this is a job better suited to tools like dbt.
In this blog post, I will show you how to create your Snowflake DataOps pipeline using AWS developer tools and Flyway.
Warning! This is a very hands-on blog post. Get ready to get your hands dirty
Let's get Started:
To get started you will need to follow below steps:
Step 1: Downloading the template
Download below repository as a zip folder. Once downloaded unzip it and cd into the folder Snowflake Dataops Repository
This repo uses below services to implement an automated deployment cycle to Snowflake. All the pipeline and related infrastructure are created through code using AWS cloudformation.
- CodeCommit
- CodeBuild
- CodePipeline
- Cloudformation
- Flyway
Step 2: Setup Snowflake Credentials
To allow your pipeline to get access to Snowflake, you will need to first create an RSA public and private key. You can create the keys using openssl by running below commands in your command line
mkdir keys
openssl genrsa 2048 | openssl pkcs8 -topk8 -inform PEM -out keys/rsa_key.p8 -nocrypt
openssl rsa -in keys/rsa_key.p8 -pubout -out keys/rsa_key.pubOnce keys are created, you then need to create a Snowflake user and assign the RSA public key to it. Run below commands on Snowflake worksheet or execute them using snowsql
Note: Remove/exclude the header and footer of the public key
create user pipeline_sys_user;
alter user pipeline_sys_user set rsa_public_key_2='MIIBIjANBgkqh...';Next, in order for your pipeline to use the private key, you must store it in AWS secrets manager.
Store the private key in aws secrets manager as plain text and remove/exclude the header and footer of the private key
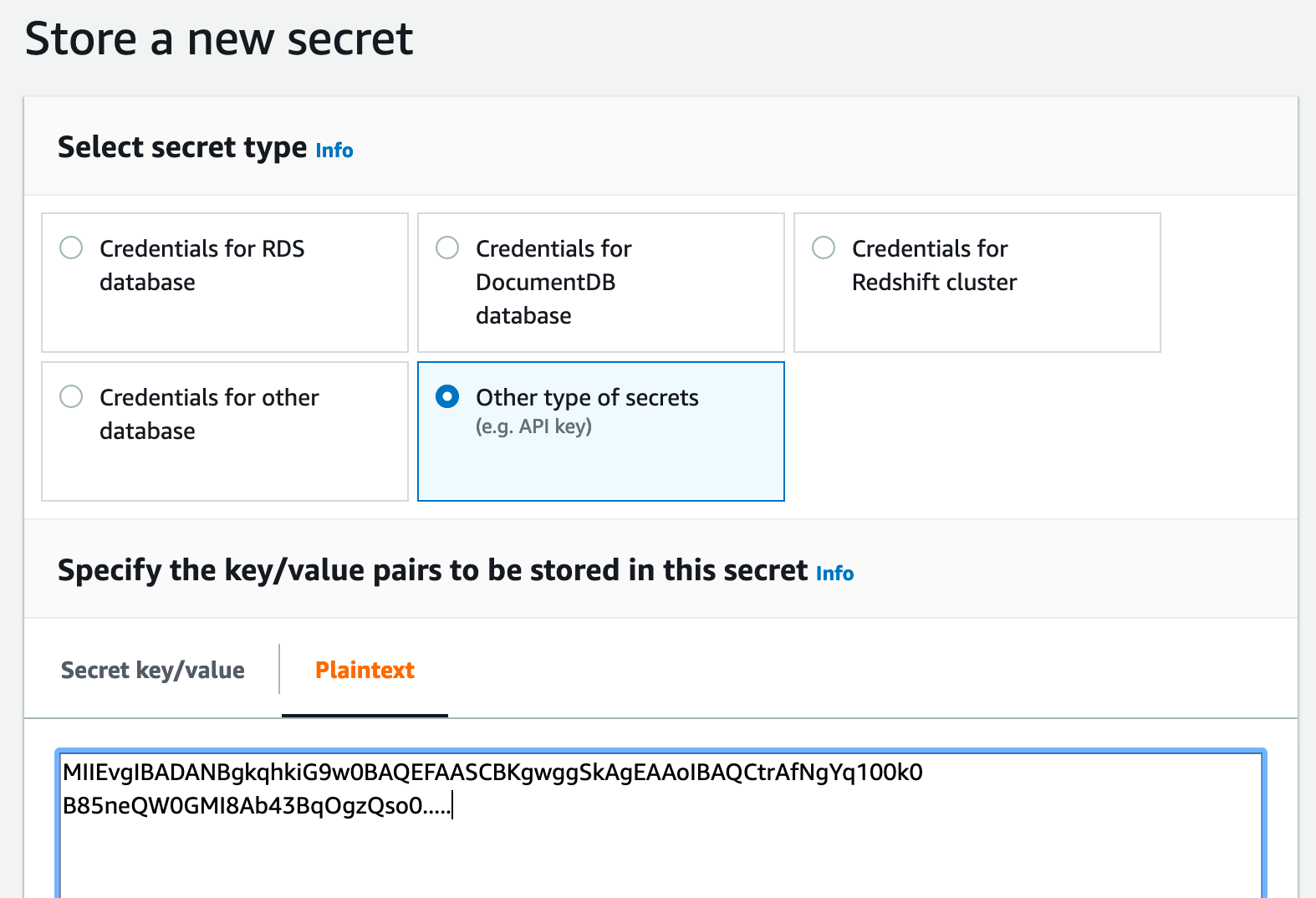 Make sure to name it "snowflake/pipeline_sys_user"
Make sure to name it "snowflake/pipeline_sys_user"
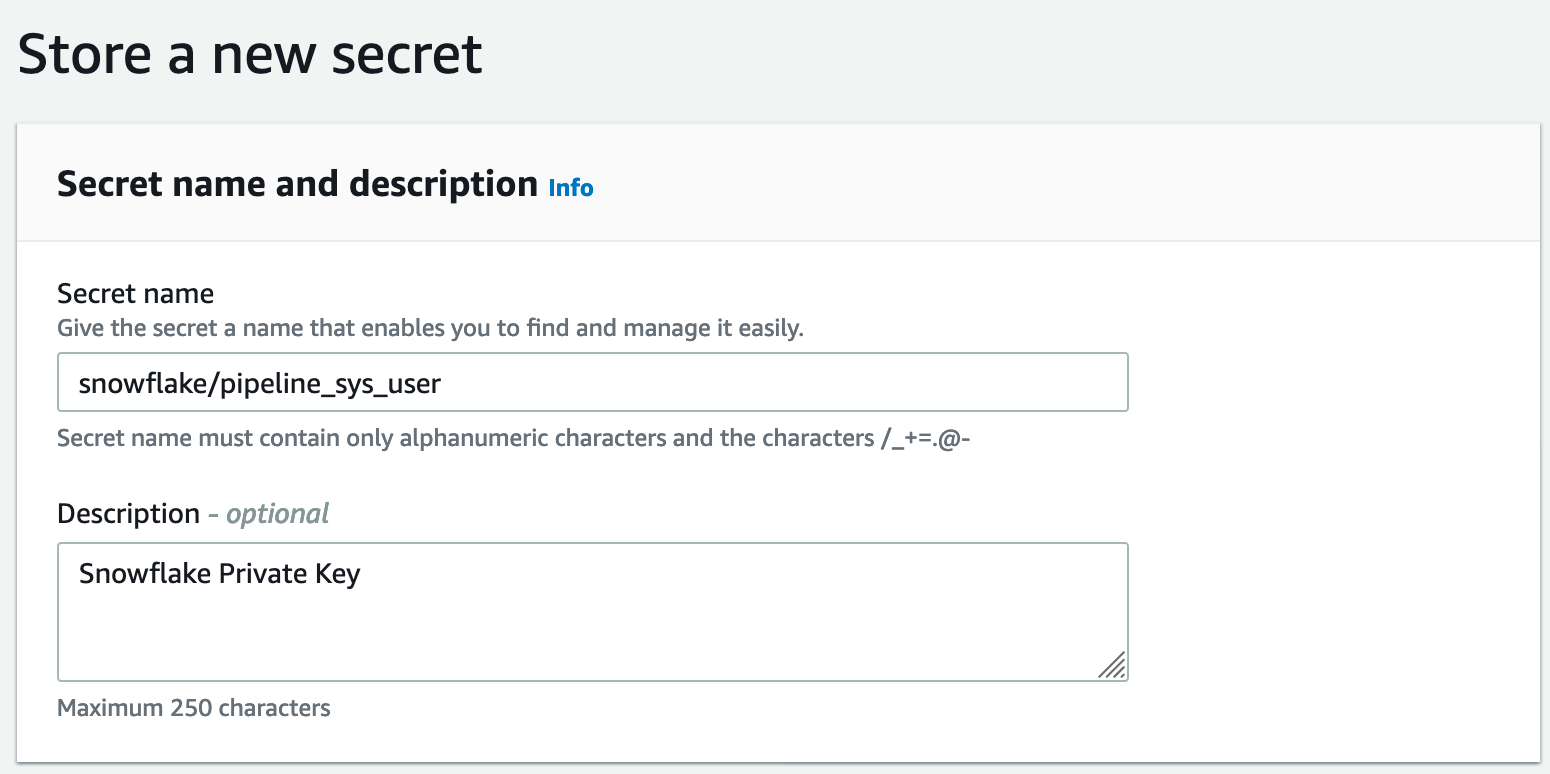
Last step is allowing code build in your pipeline to access the key in secrets manager.
To do that find out the arn of your secrets manager:
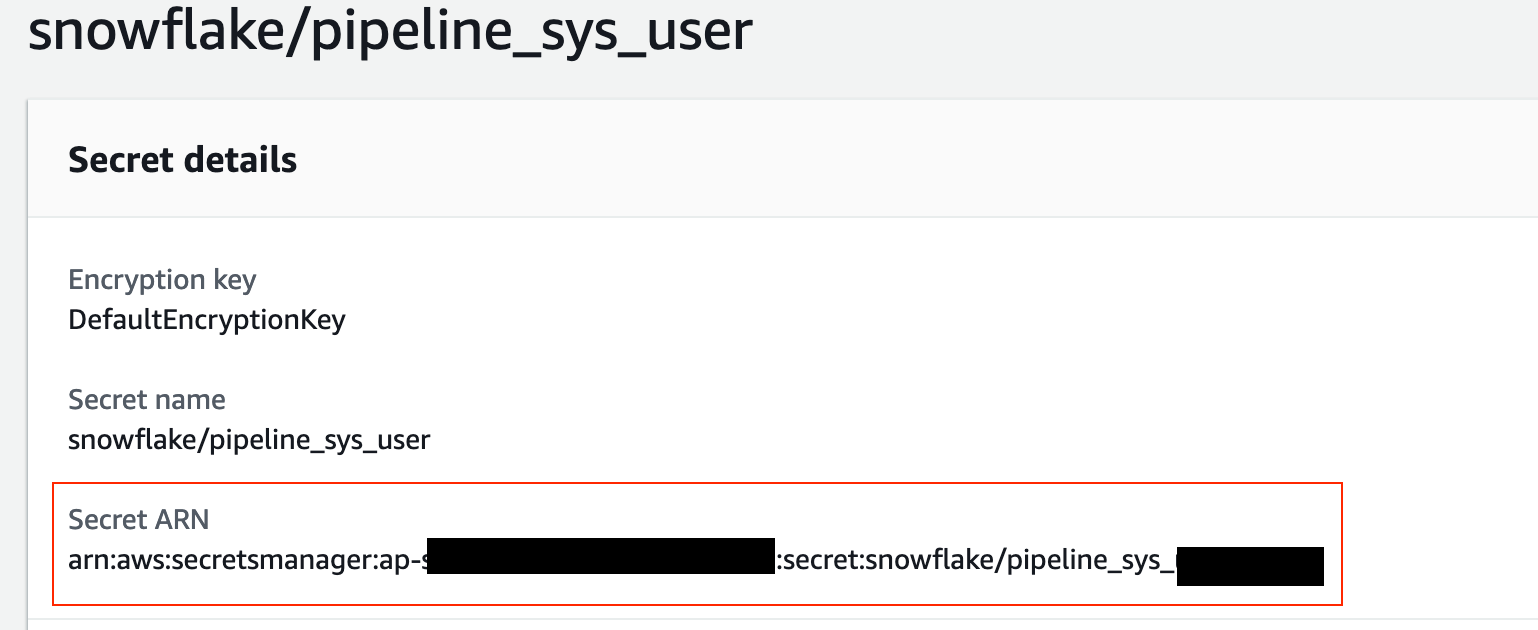 Hold onto your secrets manager arn. You will need to place it in the parameter files later.
Hold onto your secrets manager arn. You will need to place it in the parameter files later.
Step 3: Creating Snowflake resources
Now it is time to create Snowflake database, roles, grants and other resources that pipeline require in order to implement changes in snowflake. Run below commands on Snowflake worksheet or execute them using snowsql
CREATE DATABASE pipeline_db_migration_plan;
CREATE ROLE pipeline_role;
GRANT ROLE pipeline_role TO USER pipeline_sys_user;
GRANT ALL ON DATABASE pipeline_db_migration_plan TO ROLE pipeline_role;
GRANT ALL ON SCHEMA public TO ROLE pipeline_role;
CREATE WAREHOUSE pipeline_warehouse;
GRANT USAGE ON WAREHOUSE pipeline_warehouse TO ROLE pipeline_role;
// Ideally you only want to grant permissions that your pipeline requires. Granting SYSADMIN is not encouraged
grant role SYSADMIN to role pipeline_role;
Optional: In my sql scripts, I am creating tables in my_db database and my_schema schema. So if you want my template scripts run successfully on your snowflake account, you will need to run below statements too
create database my_db;
grant all on database my_db to role pipeline_role;
create schema my_schema;
grant all on schema my_schema to role pipeline_role;Step 4: Update pipeline parameters
Last step before creating your pipeline is to update parameters with the naming conventions you used to create your snowflake resources. If you have followed my naming convention you probably will not need to change anything except SnowflakeAccount and SnowflakeSecretsManagerARN. Update both parameter files pipeline/aws_seed-cli-parameters.json and aws_seed.json to match resources you created in snowflake
"SnowflakeAccount": "<ACCOUNTNAME>.<REGION>",
"SnowflakeUsername": "pipeline_sys_user",
"SnowflakeMigrationDatabaseName": "pipeline_db_migration_plan",
"SnowflakeWarehouse": "pipeline_warehouse",
"SnowflakeRole": "pipeline_role",
"SnowflakeSecretsManagerARN": "<The arn to the secrets manager that holds Snowflake private key>" {
"ParameterKey": "SnowflakeAccount",
"ParameterValue": "<ACCOUNTNAME>.<REGION>"
},
{
"ParameterKey": "SnowflakeUsername",
"ParameterValue": "pipeline_sys_user"
},
{
"ParameterKey": "SnowflakeWarehouse",
"ParameterValue": "pipeline_warehouse"
},
{
"ParameterKey": "SnowflakeMigrationDatabaseName",
"ParameterValue": "pipeline_db_migration_plan"
},
{
"ParameterKey": "SnowflakeRole",
"ParameterValue": "pipeline_role"
},
{
"ParameterKey": "SnowflakeSecretsManagerARN",
"ParameterValue": "<The arn to the secrets manager that holds Snowflake private key>"
}Step 4: Deploy your code to AWS
To deploy the infrastructure for your pipeline, you will need to first setup your aws credentials in your terminal. Once it is done, execute init.sh file. Note: the aws user/role you are running the init script as will need admin-like privileges, e.g. be able to create iam roles
sh pipeline/init.shMake sure all the steps goes through successfully. The above init script executes two major steps:
- Creating the cloudformation stack for deploying all the AWS infrastructure including CodePipeline, Codebuild and Codecommit
- Pushing your codebase into the newly created Codecommit repository
If the second step fails because of your git config settings, you will need to make sure to run them again
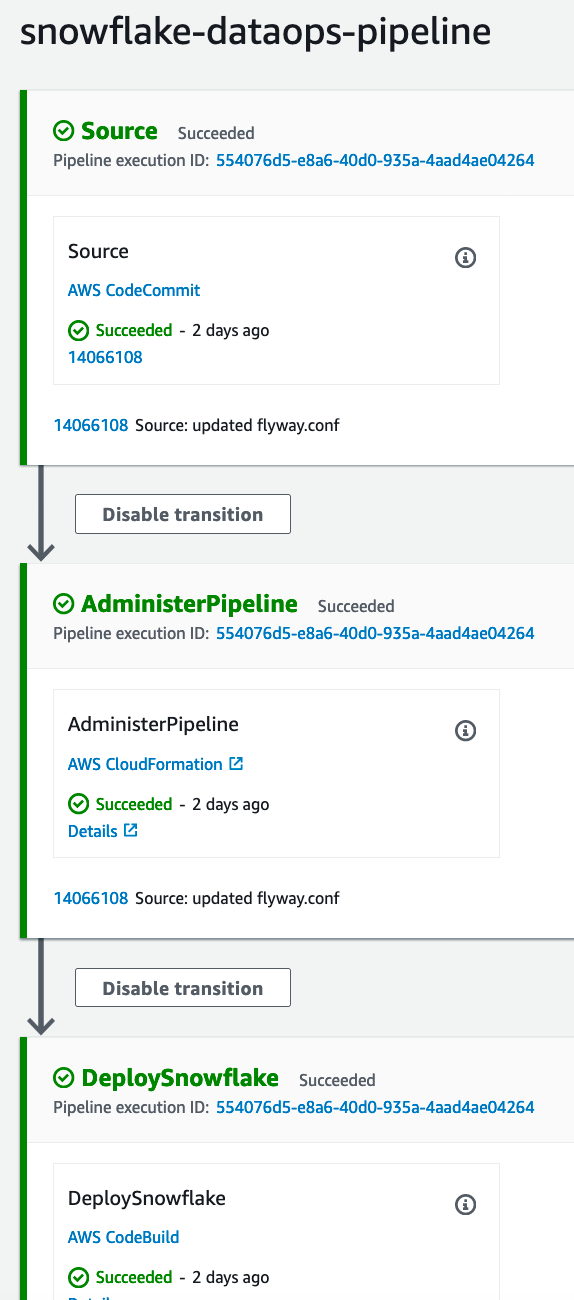
 Now you can check codepipeline and see a green end to end deployment
Now you can check codepipeline and see a green end to end deployment
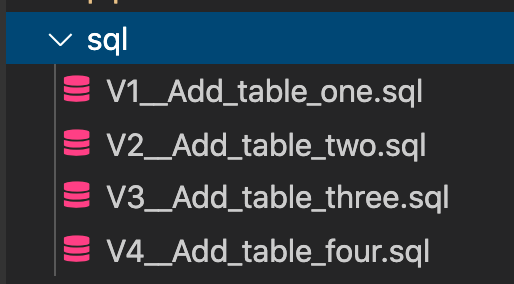
This repo uses Flyway to deploy Snowflake changes. To deploy new changes, all you need is placing your new sql scripts in the sql folder and pushing it to codecommit.
Make sure to follow Flyway naming conventions. All versioned sql files should start with V__ and repeatable scripts should start with R___
If you need any help implementing DataOps patterns and automated data pipelines in your organization, feel free to get in touch with us.