Centralised Log Management with a Data Lake hustle on the side
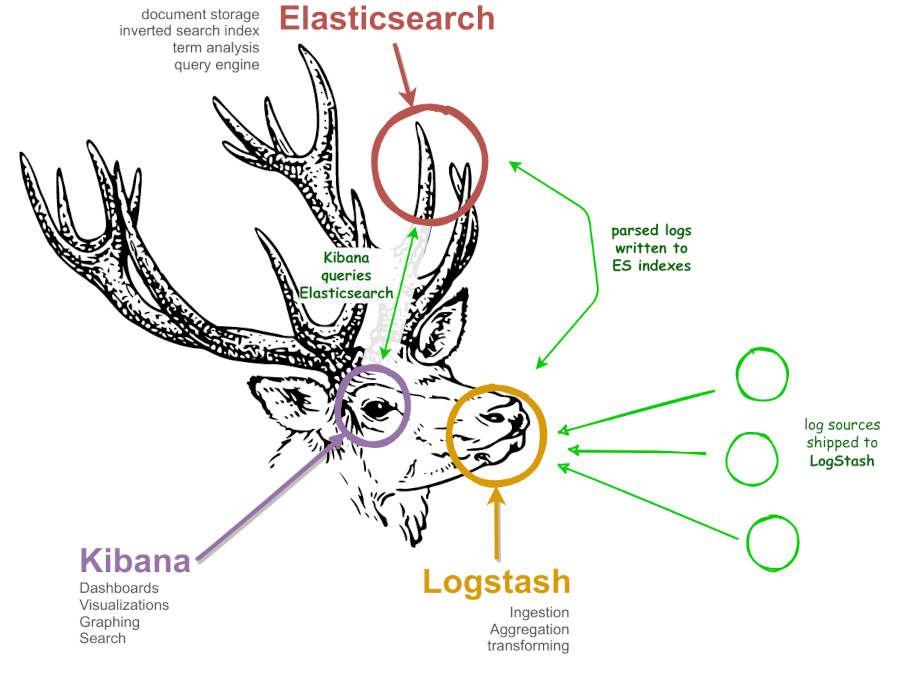
Many organisations have some form of centralised log management - or a dire need for one - and many of those will be based on Elasticsearch, Logstash and Kibana - the ELK stack. In case you don't know what that means, here's a diagram to show what each part of the ELK stack does:
By now, most large organisations will also have realised that maintaining these capabilities is a significant challenge - from rightsizing elasticsearch to ensuring high availability and striking the balance between log retention and hot storage cost.
So today, I wanted to investigate, what would it look like to create a basic cloud hosted centralised log management system, for an organisation generating log data on-premise? In our examples we will consider log sources such as
- Active Directory domain controllers
- Linux syslog files
- Application Logs
However, you can ingest any data that you are capable of shipping across your network - it could be router / traffic logs, alarm system telemetry, sensor data, etc. If you want to be able to search it, this pattern should work for you.
A core concept of this architecture is making use of Kinesis Firehose and its compatible agents to effectively replace both log shippers and the Logstash component of the ELK stack. Kinesis Firehose is a serverless delivery stream that - at its simplest - takes what you put in it, and dumps it somewhere. It currently supports destinations such as S3, ElasticSearch, RedShift and Splunk. As your requirements grow, so too can Kinesis Firehose stretch to accommodate you, both in features and pricing. For example, it can perform transformations on your behalf; compress your data; change the data format (e.g. from JSON to Parquet). While some of these features will add extra cost per GB processed, it can be a really useful tool to conform your data prior to ingestion, or provide both raw and transform data outputs from a single input stream.
Our Architecture
In summary, we will use:
- Kinesis Agent as a log shipper - additionally allowing transformation of data records before they are put on the delivery stream
- Kinesis Firehose Delivery Stream - receives parsed and aggregated data from kinesis agents, and sends them to the configured destination - in our case Elasticsearch
- Elasticsearch Service to provide Elasticsearch cluster and Kibana frontend. Elasticsearch is our hot storage layer for searching logs.
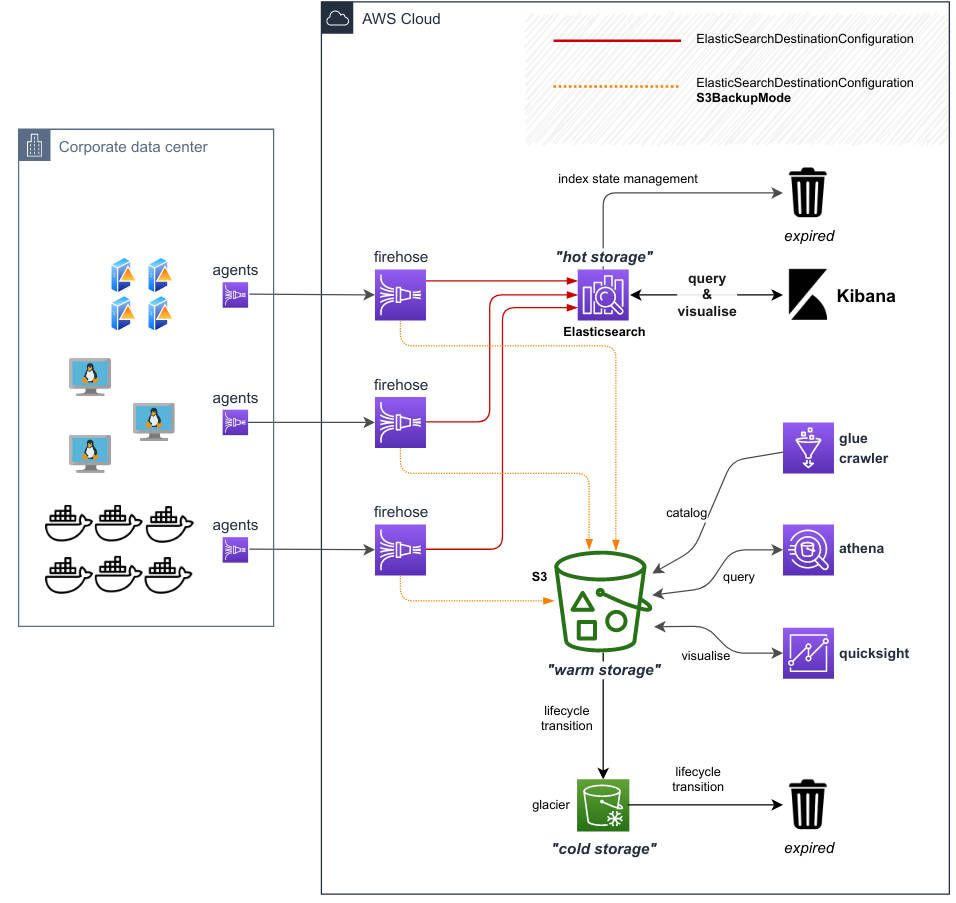
The best part of this solution is that we can leverage Firehose Delivery Stream to also save a copy of the data to S3. This allows us to write automatically to the warm storage layer at the same time as writing to Elasticsearch; therefore we can safely retire old log indices in ElasticSearch after their retention period (saving cost and improving sustainability), knowing the data is already in the warm storage layer (S3).
Limitations
It's worth calling out some limitations and restrictions.
Kinesis Firehose is not realtime, it is near realtime. Therefore you must be willing to accept the (configurable) latency. Kinesis Firehose allows you to set "hints" (e.g. write after 1Mb received or after no writes received for 1 min) but the service does not guarantee to honour them[1].
Another current limitation of Kinesis Firehose is that you are limited to having 50 Firehose Delivery Streams in a single region per account. Think of that as 50 types of data - you can have multiple clients send data of the similar "shape" to a single firehose. Now, there is nothing to stop you from setting up your Kinesis Firehose Delivery Streams in different accounts, targeting a single S3 bucket in a "data lake" account - you will just need to grant access in the S3 Bucket Policy to each of the cross account Firehose roles.
It would be great to see Kinesis Firehose evolve to support writing to S3 Access Points instead of only bucket destinations; this would reduce the operational burden and risk of managing cross account S3 access.
Firehose has some bandwidth restrictions that you need to be aware of, and note also that they vary by region - as an example, default throughput in us-east-1 tends to be greater than in ap-southeast-2
us-east-1
- 5,000 records/second, 2,000 requests/second, and 5 MiB/second
ap-southeast-2
- 1,000 records/second, 1,000 requests/second, and 1 MiB/second
In combination with a review of your existing service quotas, you will need to take these limits into consideration when assessing how many clients can send data to a single Kinesis Firehose.
Data
When many people think of ELK they might think of application logs that they may use for auditing or debugging, tracing or dashboarding. But the reality is that Elasticsearch doesn't care what you store in your indices. This can be really useful when you have data sources that are similar but have slight nuances.
For example, imagine you have firewall devices that log connection state events. Generally these may follow (e.g. syslog) a pattern, but some devices may have variations or additional data. Elasticsearch will happily accept that extra data in its documents as and when it is present [2], yet it is typical to find a general alignment of data shape between a given Kinesis Firehose and a matching Elasticsearch index.

Whilst Elasticsearch is great as a search layer or as part of a centralised log management platform, sometimes organisations want to build consistent data models around their various unconformed data sources. This is where this architecture really shines - the raw data is also written to S3 where it can later be processed into a conformed model (to iron out schema differences, clean data) for generalised reporting. This processed stage can then be accessible dynamically using tools such as AWS Athena, AWS Redshift Spectrum, Snowflake External Tables, etc. This would typically be considered a part of the warm storage layer.
Transformation
It should be noted that in this architecture you have a few different options to perform transformation:
-
In the warm storage layer (S3) using ETL tools such as AWS Glue or AWS EMR to run Spark jobs or equivalent. Transforming your data at this layer is likely to be more cost effective as you work in bulk / batch. It may also be more resilient because you always capture raw data untransformed and can re-process data as schemas adapt
-
Within the Firehose Delivery Stream - Lambda can be used to transform your data on the fly, but attracts an additional cost per Gb processed. This is a great option if you have a need to conform your data before ingesting it to your hot storage layer. However, as your schema evolves, the onus is on you to adapt your transformations at the appropriate time to ensure no loss of data.
Life-cycling
We've mentioned hot and warm storage layers - these typically refer to speed (and sometimes manner) in which data can be recalled. Typically there will also be a significant cost disparity between each storage layer - as examples, cold storage may be a tenth of the cost of warm storage, whilst warm storage may be a tenth of the cost of hot storage.
For this reason, it is essential for data architects and engineers to understand the usage patterns of each kind of data they work with, to ensure they adequately balance the way the data will be consumed against the cost of storing and computing that data.
Looking at our example sources, we may have the following requirements:
| Event Source | Hot Storage Retention | Warm Storage Retention | Cold Storage Retention | |-|-|-|-|-| | AD Domain Controllers | 14 days | 30 days | 365 days | | Linux syslogs | 7 days | 60 days | 120 days| | Application Logs | 28 days | 180 days | 730 days |
In the table above we show the retention period - but how does data actually transition between the layers? There are many ways it can be achieved, but we will focus on the simplest:
- Making use of Kinesis Firehose's backup mode to write raw data to S3 as well as Elasticsearch
- Utilising S3 Lifecycle rules to transition data to other tiers or deletion after a given period
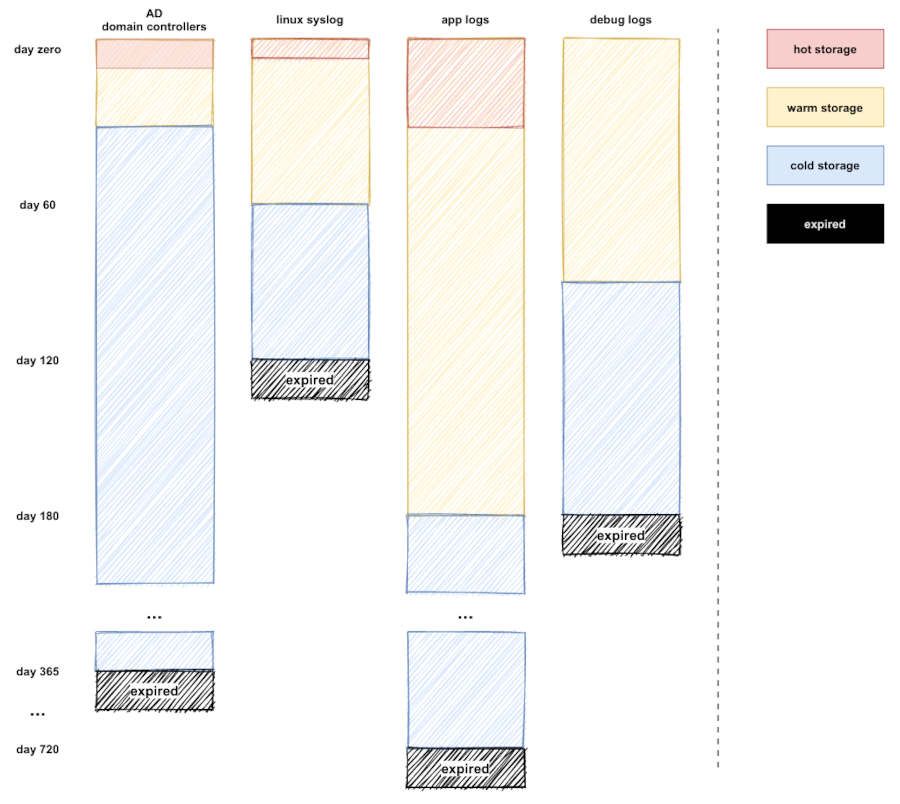
The advantage of this system is that we are not writing any code to move data around. This is important for a number of reasons
- we gain resilience from not writing data / schema specific code
- we leverage the cloud platform capabilities to guarantee at least once delivery semantics
- we can set individual retention schedules dependent on the requirements of each data kind, but at the infrastructure / managed service layer, instead of our own code
This makes for a sustainable growth trajectory for our log management system. As costs increase we can re-evaluate our needs and adjust retention schedules if necessary, or alternatively, bypass hot storage layers altogether.
Curation and Maintenance
Now, you can point any of your scalable compute services mentioned above to the raw data on your warm storage bucket and search your data, but with any significant volume of data you will likely find that the performance is not what you would expect, and that's because the raw data that Firehose is writing to S3 is being written in micro batches (every 2 minutes or every 20Mb, as examples).
This is commonly referred to as the small file problem and though it's described as a problem it's more accurately a Diseconomy of Scale - as the number of files increases, the more non value add activities have to be run:
- listing bucket files
- bucket file fetching
- content decryption
- tcp negotiation
- ssl handshaking
For a few files the effect is negligible, however when you scale it to thousands of files and many concurrent users, it is very noticeable. The solution is to periodically create rollups [3] of those files. This is commonly done with Spark jobs that will aim to:
- rewrite data into columnar formats such as Parquet for optimised reading
- compress the data for better performance and storage density
- compact many small files in to larger files optimised for scalable compute query engines
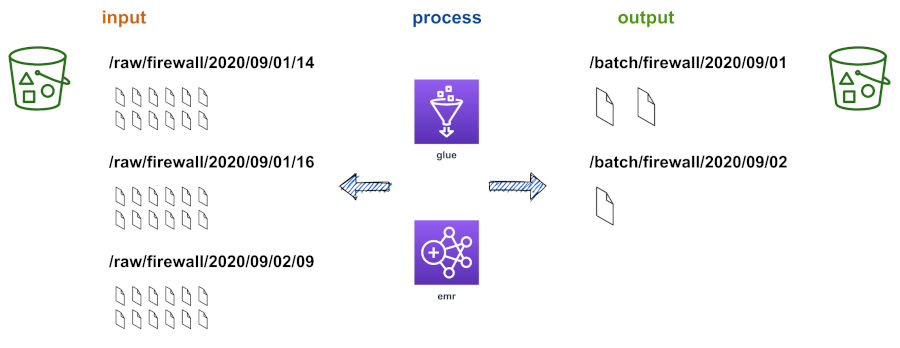
There are many different ways to achieve this goal - a few are outlined below
| method | pros | cons |
|---|---|---|
| EMR Cluster Spark Jobs | - pre-baked hadoop environment- transient clusters with spot instances could be cheaper | - high complexity |
| Glue PySpark/Scala Jobs | - serverless- simple | - More expensive at scale |
| Airflow / Luigi, etc. | - Full Workflow Management for your ETL | - not cloud native- operational complexity |
| Kinesis Firehose Transformations | - Embedded transformation- Backup mode to allow capturing raw data | - Poor Documentation- May see poor economies of scale with high throughput |
Final Words
I hope this blog post has inspired some ideas to make you think about the way you use your log data and organise your data platforms.
If centralised log management is truly all you are looking for, you should seriously consider managed services such as Sumo Logic or the managed offerings from Elastic, as it may be more cost effective and simpler to manage operationally. Yet for many people, centralised log management is a stepping stone to building a cohesive organisational data strategy and meeting the needs of their data consumers with cloud native technologies.
Contact us at Mechanical Rock to talk about your data ambitions and how we can help!
References
[1] https://docs.aws.amazon.com/firehose/latest/APIReference/API_BufferingHints.html