Story telling App with Amazon Bedrock
Initial Words
Welcome to Part 2 of our introductory blog series! In Part 1, we delved into the basic concepts such as Foundation Models and discovered the amazing features and capabilities of Amazon Bedrock. Now, it's time for the fun part: building your very own storytelling application with Foundation Models from Amazon Bedrock.
By the time we're done here, you'll have deployed a serverless setup with two APIs. First API will generate the story from a given topic, and the other one will illustrate each paragraph of the story. We'll be using Appsync and GraphQL to make requests to these APIs and generate stories. If you're wondering how these APIs work with FM models to create stories and illustrations, that's the magic of Amazon Bedrock we'll uncover together. So, let's get started on this storytelling adventure!
Now that you've got a glimpse of what we're building, let's take a moment to unravel the complexity hidden behind this simple GenAI tool.
Imagine this: a user hops onto your web app and wants to create a story by giving it a topic prompt. From the user's standpoint, they expect the story to magically unfold, complete with illustrations, as quickly as they can think of it. They might want to edit and personalise the story, or even ensure that it suits the age group it's intended for. And what if they want to save and share their literary masterpiece with others?
All these amazing features and optimisations are like extra layers of icing on the cake, but for our project, we're keeping things simple and focused. So, while they're fascinating possibilities, we'll save them for another time!
Build An Storytelling App With Me
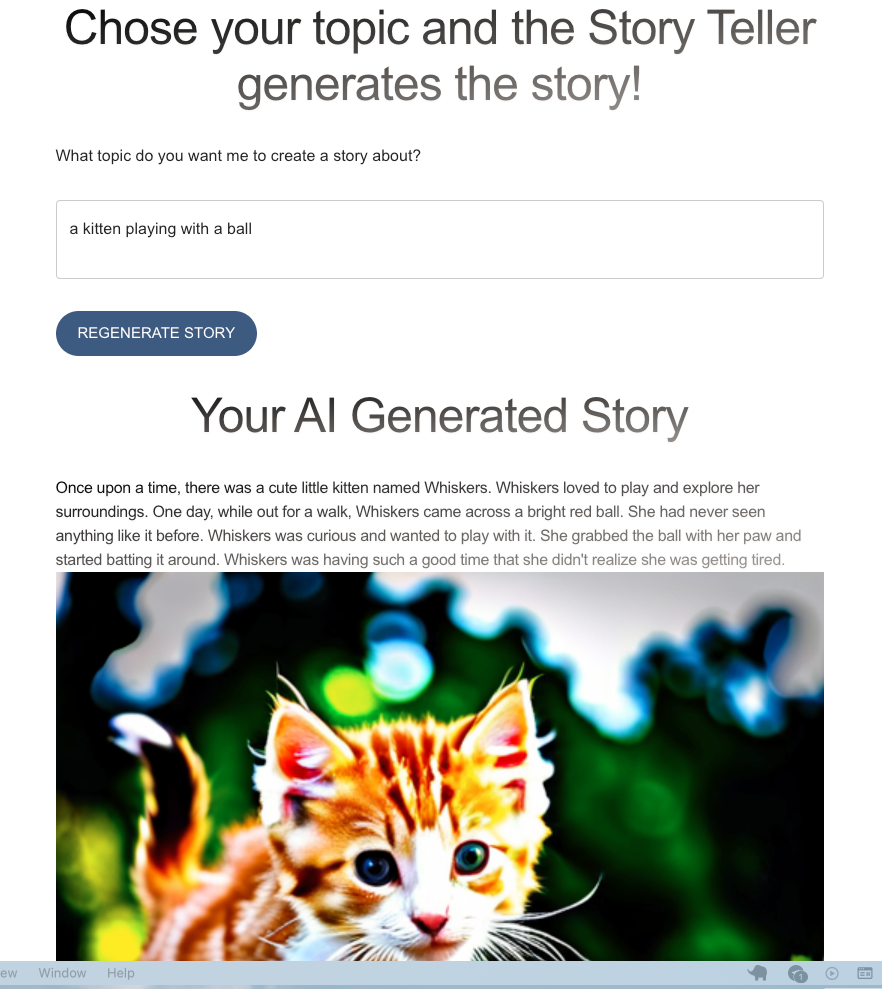
Take a look at the solution diagram below! It shows you exactly how our app works at every step:
-
The user starts by giving us a topic for their story.
-
When user clicks on "Generate Story," the web app sends a request to foundation model to create the story, and then it returns the generated story. The Frontend app does some cleaning on the API response and shows the story in separate paragraphs.
-
Now, here's where it gets interesting. They can add illustrations to the story! In this app, I've configured the FM model to generate an image for summary of each paragraph.
-
These generated images are stored in an S3 bucket, and the UI shows them to user once it gets back the S3 presigned URLs.
For all the nitty-gritty details, just check out the solution architecture diagram. It's like a map that guides you through the app's awesomeness.
Architecture
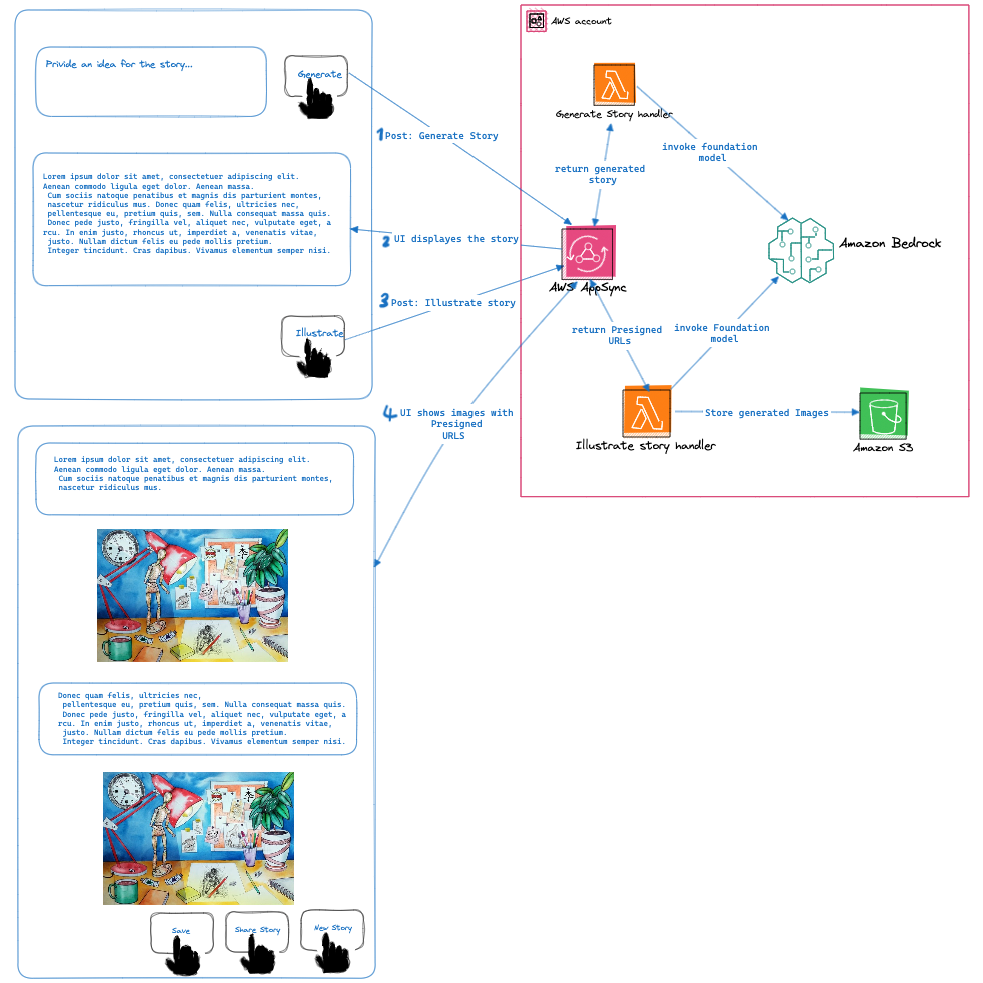
Web application
For UI facing of this GenAI tool, we won't be diving into the fancy design. I've laid out the basic structure of the application. You can grab the source code from this repository. Feel free to give it your own unique style or add more features if you'd like. Once you've got the code, just follow the simple steps in the ReadMe file to get your app running on your computer.
And if you're feeling adventurous and want to share your app with the world, you can host it on your AWS account. I won't get into the nitty-gritty details of that in this blog post, but all you really need is an Amazon S3 bucket to store your web app's resources. Then, set up Amazon CloudFront and use Route 53 to manage your domain's traffic and routing. It's not as complicated as it might sound, and it's a great way to take your project to the next level!
Amazon Bedrock Magician
To set up the necessary APIs for our app to function, we'll be creating a serverless stack. You can access the complete source code in this GitHub Repo. In this repository, you'll find the required Lambda functions as the API resolvers, IAM Roles, Amazon Appsync, S3 Bucket and all the managed Policies listed in the "serverless.yml" file. To deploy the Backend resources, all you have to do is run the command specified in the "ReadMe.md" file.
However, I strongly recommend that before you deploy the serverless stack, you continue reading this article. I'll be sharing code snippets from various lambdas, explaining how to define your Input Prompt, how to access the API "Request" object, and different methods for invoking the Foundation Models for both Python and Nodejs project. It's like getting a sneak peek behind the scenes!
Configure the Bedrock runtime Client
Typically, when you need to issue commands to an AWS service, the first step involves initialising the service client. In this scenario, we'll initialise the Amazon Bedrock Runtime client.
Code snippets in Python and Nodejs:
# Implementation in Python
import boto3, json
bedrock_client = boto3.client(
service_name="bedrock-runtime",
region_name="us-east-1"
)
// Implementation in Nodejs
import { BedrockRuntimeClient } from "@aws-sdk/client-bedrock-runtime";
const bedrockRuntimeClient = new BedrockRuntimeClient({ region: "us-east-1" })
Model playground
Before Prompt engineering and constructing our request's payload, let's understand how to send requests for each Bedrock model. For that, you have two options. You can check out the Notebook examples in the Bedrock console, or you can use the model playground.
In the model playground, select the model you want, configure the inference options (the model parameters will impact the result), and then click "View API Request." This allows you to copy the request and modify the input as needed.
For our Generate Story API, we'll be using the "Jurassic-2 Ultra" model from the "AI21 Lab" category. Let's see how to get the api request example for this model. It's going to be a fun ride!
Within the Text playground, I select the category and model:
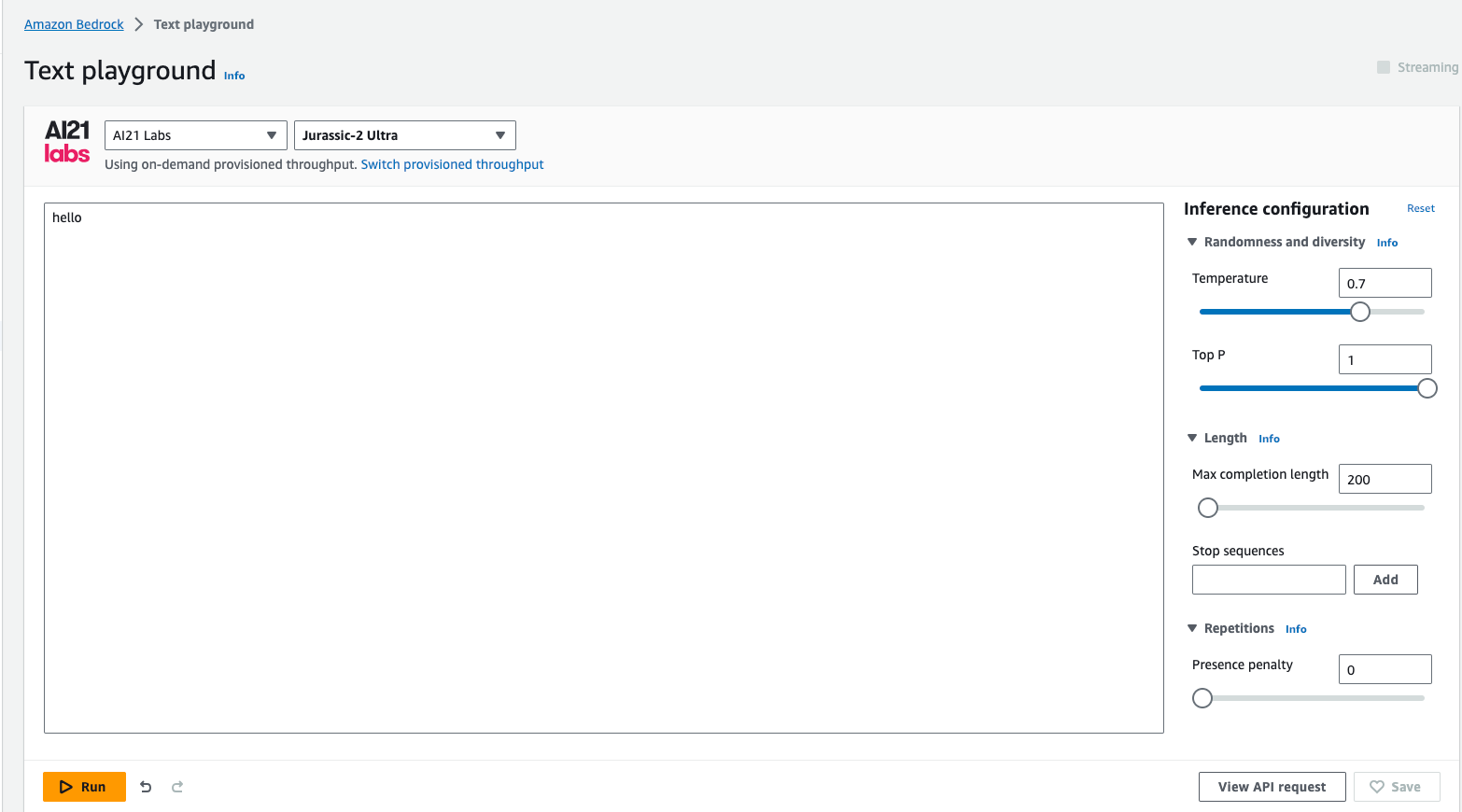
Next, type a random text, instead of invoking the model, select the "View API Request" from the screen and that will provide you with a request example to start with:
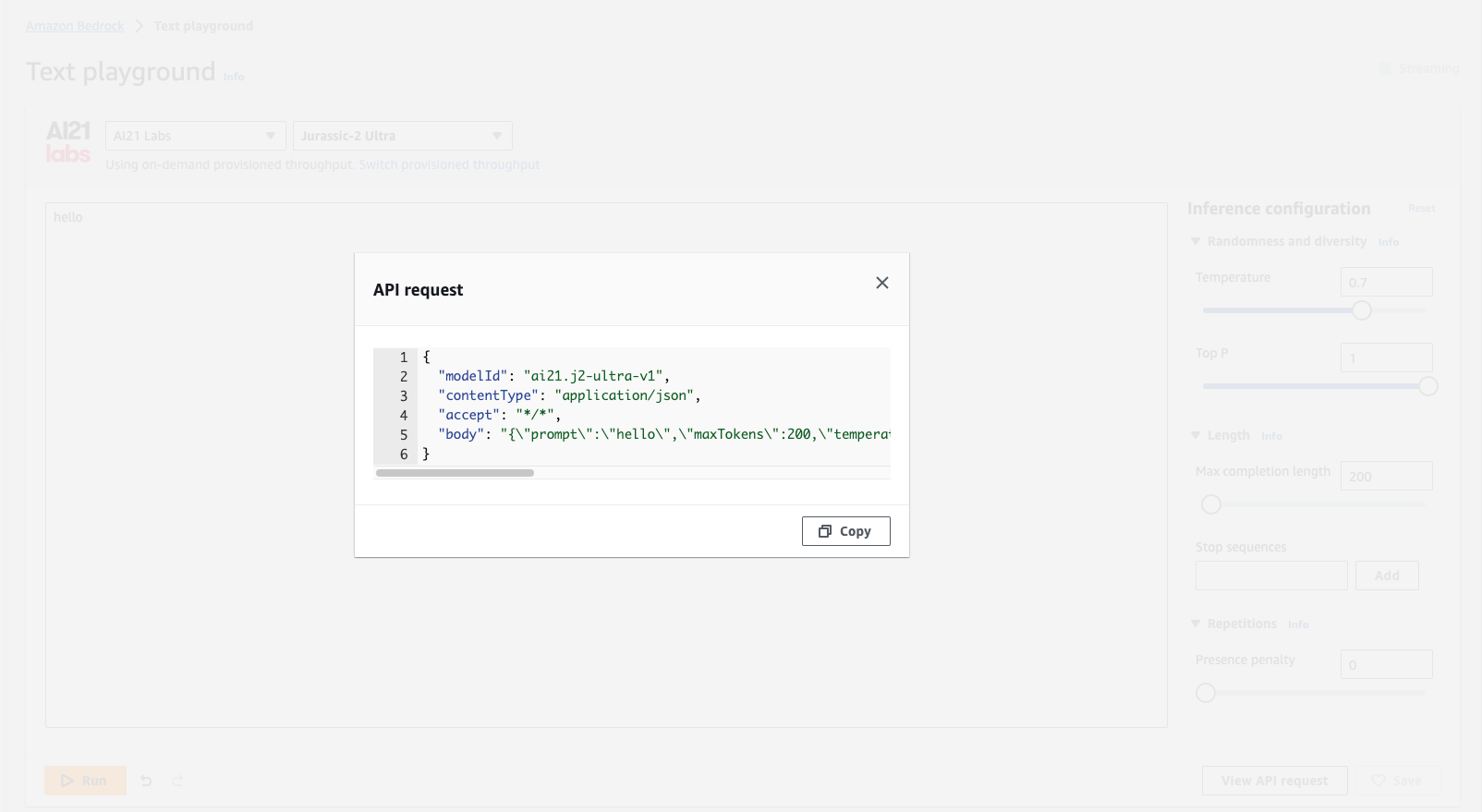
Copy the API request payload and continue with next step where I show you how to construct your Prompt and your invoke command input.
Construct your Request Payload
Now that we have the request payload, we can begin making it more versatile, allowing our model to generate stories for any given topic. Here is an example of the Text generator model API request, where we configure the "Model Id", "Model Parameters" and the "Input Prompt".
kwargs = {
"modelId": "ai21.j2-ultra-v1", <------ Text generator model
"contentType": "application/json",
"accept": "*/*",
"body": "{\"prompt\":\" write a stroy up to 400 words about "+ storyTopic + "\",\"maxTokens\":300,\"temperature\":0.7,\"topP\":1,\"stopSequences\":[],\"countPenalty\":{\"scale\":0},\"presencePenalty\":{\"scale\":0},\"frequencyPenalty\":{\"scale\":0}}" <-------- Body Object contains the Model Parameters & Input prompt
}
// Implementation in Nodejs
private constructStoryRequestPayload = (prompt: string, maxToken: number) => {
return {
"modelId": this.textModelId,
"contentType": "application/json",
"accept": "*/*",
"body": `{\"prompt\":\ ${prompt},\"maxTokens\": ${maxToken},\"temperature\":0.7,\"topP\":1,\"stopSequences\":[],\"countPenalty\":{\"scale\":0},\"presencePenalty\":{\"scale\":0},\"frequencyPenalty\":{\"scale\":0}}`
}
}
Invoke FM for inference
We're nearly there! It's as straightforward as this. The final step is to invoke the model (in this case, the text generator model "Jurassic-2 Ultra") and obtain inference. To get inference from models in Amazon Bedrock, we have two options. We can either use the "invoke_model" method or the "invoke_model_with_response_stream" method.
If you're wondering about the difference, here's the scoop:
- With the "invoke_model" method, the model won't provide any response until it has fully generated the text or completed the requested task.
- On the other hand, "invoke_model_with_response_stream" offers a smoother and more real-time experience for users. It sends stream response payloads back to clients as the model works its magic.
Code snippets for model inference:
# Implementation in Python
# invoke_model
story = bedrock_client.invoke_model(**kwargs)
# invoke_model_with_response_stream
story = bedrock_client.invoke_model_with_response_stream(**kwargs)
stream = story.get('body)
if stream:
for event in stream:
chunk = event.get('chunk)
if chunk:
print(json.loads(chunk.get('bytes').get('completion'), end=""))
// Implementation in Nodejs
private invokeTextModel = async (prompt: string, maxToken: number): Promise<string> => {
// construct model API payload
const input = this.constructStoryRequestPayload(prompt, maxToken)
const command = new InvokeModelCommand(input);
// InvokeModelRequest
const response = await this.bedrockRuntimeClient.send(command);
const story = response.body.transformToString()
// get the text body
const parsedStory = JSON.parse(story)
return parsedStory.completions[0].data.text
}
With three simple steps we could generate the story from a topic! API response is returned in Json format and all we need to do is to destruct the generated text from response object.
Extract the generated text
Here is the steps to extract the story content from the API response:
story_stream = json.loads(story.get('body').read())
story_content = story_stream.get('completions')[0].get('data').get('text')
We still need another API to complete the Story Telling app. To create illustrations based on a generated story, repeat the 3 simple steps from previous API and simply utilise the "stable-diffusion-xl-v0" model from the "Stability AI" category to generate image based on the provided content. It's that easy!
Final Words
I've always been a fan of keeping things simple and staying grounded in the fundamentals. It's a great way to uncover new ideas, explore, and learn, all while having a good time building cool stuff.
In this two-part blog post, my goal was to introduce you to Amazon Bedrock, showcase its features, and demonstrate how you can easily integrate various FMs into your APIs to build amazing generative AI-powered applications.
I hope you've found it valuable. Now that you have a solid foundation of Amazon Bedrock and you know how to get inference from a basic model within Amazon Bedrock in 3 simple steps feel free to build upon it and explore even further! The possibilities are endless.